“精度”用FP8训练大模型有多香?微软:比BF16快64%,省42%内存
今天,很高兴为大家分享来自机器之心Pro的用FP8训练大模型有多香?微软:比BF16快64%,省42%内存,如果您对用FP8训练大模型有多香?微软:比BF16快64%,省42%内存感兴趣,请往下看。
低精度训练是大模型训练中扩展模型大小,节约训练成本的最关键技术之一。相比于当前的 16 位和 32 位浮点混合精度训练,使用 FP8 8 位浮点混合精度训练能带来 2 倍的速度提升,节省 50% - 75% 的显存和 50% - 75% 的通信成本,而且英伟达最新一代卡皇 H100 自带良好的 FP8 硬件支持。但目前业界大模型训练框架对 FP8 训练的支持还非常有限。最近,微软提出了一种用于训练 LLM 的 FP8 混合精度框架 FP8-LM,将 FP8 尽可能应用在大模型训练的计算、存储和通信中,使用 H100 训练 GPT-175B 的速度比 BF16 快 64%,节省 42% 的内存占用。更重要的是:它开源了。
大型语言模型(LLM)具有前所未有的语言理解和生成能力,但是解锁这些高级的能力需要巨大的模型规模和训练计算量。在这种背景下,尤其是当我们关注扩展至 OpenAI 提出的超级智能 (Super Intelligence) 模型规模时,低精度训练是其中最有效且最关键的技术之一,其优势包括内存占用小、训练速度快,通信开销低。目前大多数训练框架(如 Megatron-LM、MetaSeq 和 Colossal-AI)训练 LLM 默认使用 FP32 全精度或者 FP16/BF16 混合精度。
但这仍然没有推至极限:随着英伟达 H100 GPU 的发布,FP8 正在成为下一代低精度表征的数据类型。理论上,相比于当前的 FP16/BF16 浮点混合精度训练,FP8 能带来 2 倍的速度提升,节省 50% - 75% 的内存成本和 50% - 75% 的通信成本。
尽管如此,目前对 FP8 训练的支持还很有限。英伟达的 Transformer Engine (TE),只将 FP8 用于 GEMM 计算,其所带来的端到端加速、内存和通信成本节省优势就非常有限了。
但现在微软开源的 FP8-LM FP8 混合精度框架极大地解决了这个问题:FP8-LM 框架经过高度优化,在训练前向和后向传递中全程使用 FP8 格式,极大降低了系统的计算,显存和通信开销。

论文地址:https://arxiv.org/abs/2310.18313
开源框架:https://github.com/Azure/MS-AMP
实验结果表明,在 H100 GPU 平台上训练 GPT-175B 模型时, FP8-LM 混合精度训练框架不仅减少了 42% 的实际内存占用,而且运行速度比广泛采用的 BF16 框架(即 Megatron-LM)快 64%,比 Nvidia Transformer Engine 快 17%。而且在预训练和多个下游任务上,使用 FP8-LM 训练框架可以得到目前标准的 BF16 混合精度框架相似结果的模型。
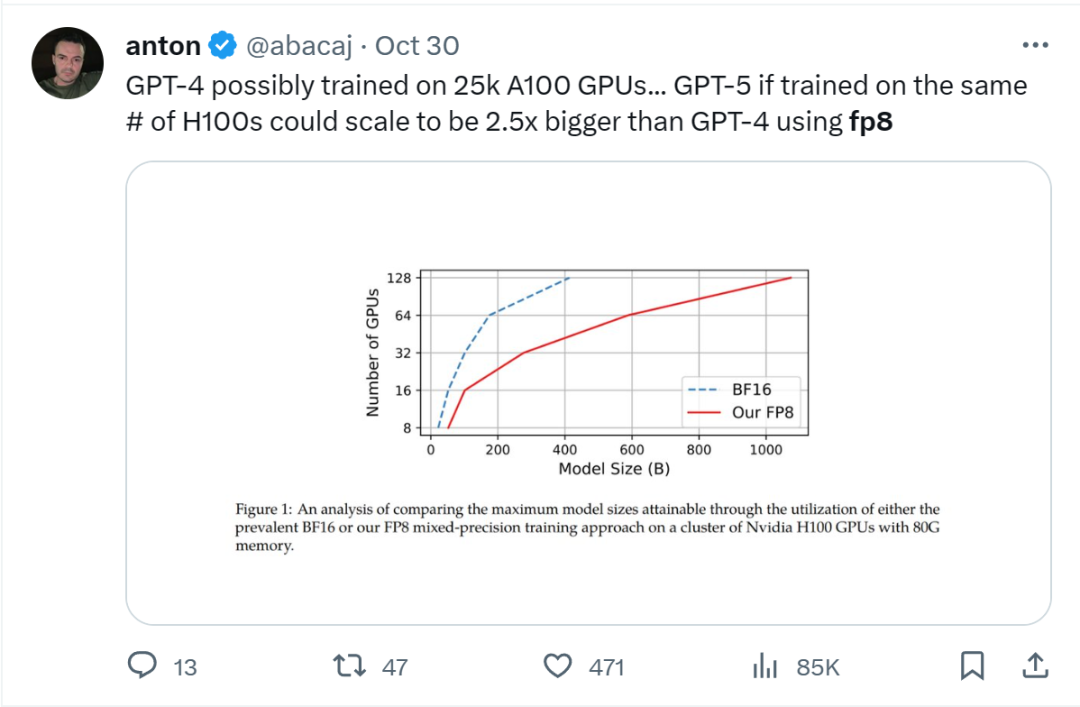
在给定计算资源情况下,使用 FP8-LM 框架能够无痛提升可训练的模型大小多达 2.5 倍。有研发人员在推特上热议:如果 GPT-5 使用 FP8 训练,即使只使用同样数量的 H100,模型大小也将会是 GPT-4 的 2.5 倍!
Huggingface 研发工程师调侃:「太酷啦,通过 FP8 大规模训练技术,可以实现计算欺骗!」

FP8-LM 主要贡献:
一个新的 FP8 混合精度训练框架。其能以一种附加方式逐渐解锁 8 位的权重、梯度、优化器和分布式训练,这很便于使用。这个 8 位框架可以简单直接地替代现有 16/32 位混合精度方法中相应部分,而无需对超参数和训练方式做任何修改。此外,微软的这个团队还发布了一个 PyTorch 实现,让用户可通过少量代码就实现 8 位低精度训练。
一个使用 FP8 训练的 GPT 式模型系列。他们使用了新提出的 FP8 方案来执行 GPT 预训练和微调(包括 SFT 和 RLHF),结果表明新方法在参数量从 70 亿到 1750 亿的各种大小的模型都颇具潜力。他们让常用的并行计算范式都有了 FP8 支持,包括张量、流水线和序列并行化,从而让用户可以使用 FP8 来训练大型基础模型。他们也以开源方式发布了首个基于 Megatron-LM 实现的 FP8 GPT 训练代码库。
FP8-LM 实现
具体来说,对于使用 FP8 来简化混合精度和分布式训练的目标,他们设计了三个优化层级。这三个层级能以一种渐进方式来逐渐整合 8 位的集体通信优化器和分布式并行训练。优化层级越高,就说明 LLM 训练中使用的 FP8 就越多。
此外,对于大规模训练(比如在数千台 GPU 上训练 GPT-175B),该框架能提供 FP8 精度的低位数并行化,包括张量、训练流程和训练的并行化,这能铺就通往下一代低精度并行训练的道路。
张量并行化是将一个模型的各个层分散到多台设备上,从而将权重、梯度和激活张量的分片放在不同的 GPU 上。
为了让张量并行化支持 FP8,微软这个团队的做法是将分片的权重和激活张量转换成 FP8 格式,以便线性层计算,从而让前向计算和后向梯度集体通信全都使用 FP8。
另一方面,序列并行化则是将输入序列切分成多个数据块,然后将子序列馈送到不同设备以节省激活内存。
如图 2 所示,在一个 Transformer 模型中的不同部分,序列并行化和张量并行化正在执行,以充分利用可用内存并提高训练效率。

而对于 ZeRO(零冗余优化器 / Zero Redundancy Optimizer),却无法直接应用 FP8,因为其难以处理与 FP8 划分有关的缩放因子。因此针对每个张量的缩放因子应当沿着 FP8 的划分方式分布。
为了解决这个问题,研究者实现了一种新的 FP8 分配方案,其可将每个张量作为一个整体分散到多台设备上,而不是像 ZeRO 方法一样将其切分成多个子张量。该方法是以一种贪婪的方式来处理 FP8 张量的分配,如算法 1 所示。

具体来说,该方法首先根据大小对模型状态的张量排序,然后根据每个 GPU 的剩余内存大小将张量分配到不同的 GPU。这种分配遵循的原则是:剩余内存更大的 GPU 更优先接收新分配的张量。通过这种方式,可以平滑地沿张量分配张量缩放因子,同时还能降低通信和计算复杂度。图 3 展示了使用和不使用缩放因子时,ZeRO 张量划分方式之间的差异。

使用 FP8 训练 LLM 并不容易。其中涉及到很多挑战性问题,比如数据下溢或溢出;另外还有源自窄动态范围的量化错误和 FP8 数据格式固有的精度下降问题。这些难题会导致训练过程中出现数值不稳定问题和不可逆的分歧问题。为了解决这些问题,微软提出了两种技术:精度解耦(precision decoupling)和自动缩放(automatic scaling),以防止关键信息丢失。
精度解耦
精度解耦涉及到解耦数据精度对权重、梯度、优化器状态等参数的影响,并将经过约简的精度分配给对精度不敏感的组件。
针对精度解耦,该团队表示他们发现了一个指导原则:梯度统计可以使用较低的精度,而主权重必需高精度。
更具体而言,一阶梯度矩可以容忍较高的量化误差,可以配备低精度的 FP8,而二阶矩则需要更高的精度。这是因为在使用 Adam 时,在模型更新期间,梯度的方向比其幅度更重要。具有张量缩放能力的 FP8 可以有效地将一阶矩的分布保留成高精度张量,尽管它也会导致精度出现一定程度的下降。由于梯度值通常很小,所以为二阶梯度矩计算梯度的平方可能导致数据下溢问题。因此,为了保留数值准确度,有必要分配更高的 16 位精度。
另一方面,他们还发现使用高精度来保存主权重也很关键。其根本原因是在训练过程中,权重更新有时候会变得非常大或非常小,对于主权重而言,更高的精度有助于防止权重更新时丢失信息,实现更稳定和更准确的训练。
在该实现中,主权重有两个可行选项:要么使用 FP32 全精度,要么使用带张量缩放的 FP16。带张量缩放的 FP16 的优势是能在无损于准确度的前提下节省内存。因此,新框架的默认选择是使用带张量缩放的 FP16 来存储优化器中的主权重。在训练中,对于 FP8 混合精度优化器,每个参数需要 6 个字节的内存:

相比于之前的解决方案,这种新的低位数优化器可将内存足迹降低 2.6 倍。值得说明的是:这是首个用于 LLM 训练的 FP8 优化器。实验表明 FP8 优化器能在从 1.25 亿到 1750 亿参数的各种模型大小下保持模型准确度。
自动缩放
自动缩放是为了将梯度值保存到 FP8 数据格式的表征范围内,这需要动态调整张量缩放因子,由此可以减少 all-reduce 通信过程中出现的数据下溢和溢出问题。
具体来说,研究者引入了一个自动缩放因子 μ,其可以在训练过程中根据情况变化。
实验结果
为了验证新提出的 FP8 低精度框架,研究者实验了用它来训练 GPT 式的模型,其中包括预训练和监督式微调(SFT)。实验在 Azure 云计算最新 NDv5 H100 超算平台上进行。
实验结果表明新提出的 FP8 方法是有效的:相比于之前广泛使用 BF16 混合精度训练方法,新方法优势明显,包括真实内存用量下降了 27%-42%(比如对于 GPT-7B 模型下降了 27%,对于 GPT-175B 模型则下降了 42%);权重梯度通信开销更是下降了 63%-65%。
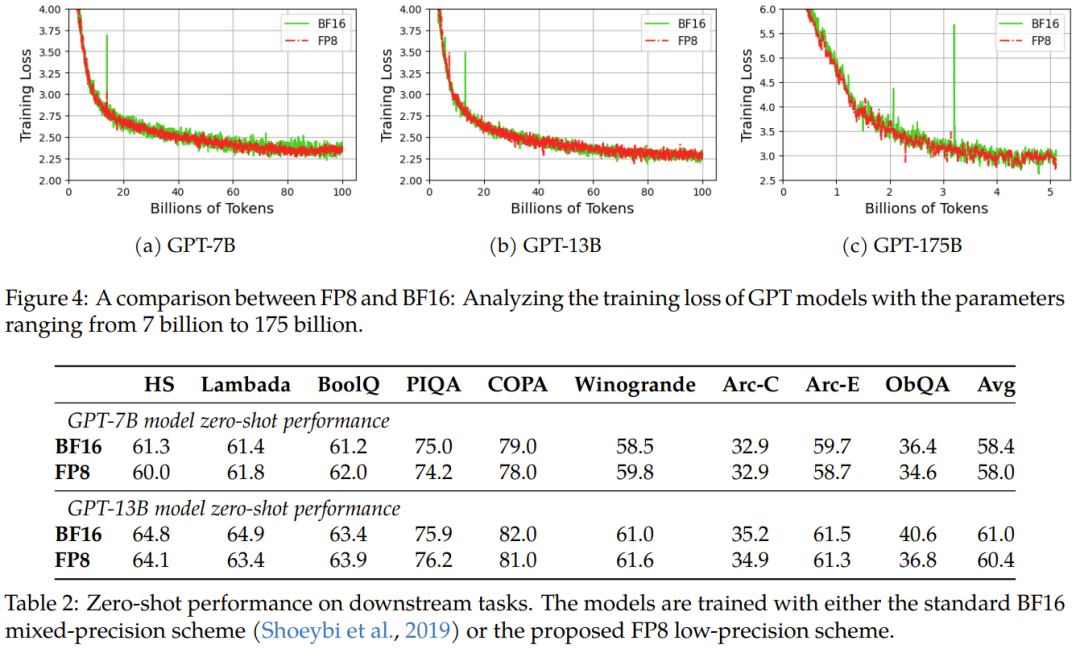
不修改学习率和权重衰减等任何超参数,不管是预训练任务还是下游任务,使用 FP8 训练的模型与使用 BF16 高精度训练的模型的表现相当。值得注意的是,在 GPT-175B 模型的训练期间,相比于 TE 方法,在 H100 GPU 平台上,新提出的 FP8 混合精度框架可将训练时间减少 17%,同时内存占用少 21%。更重要的是,随着模型规模继续扩展,通过使用低精度的 FP8 还能进一步降低成本,如图 1 所示。

对于微调,他们使用了 FP8 混合精度来进行指令微调,并使用了使用人类反馈的强化学习(RLHF)来更好地将预训练后的 LLM 与终端任务和用户偏好对齐。

结果发现,在 AlpacaEval 和 MT-Bench 基准上,使用 FP8 混合精度微调的模型与使用半精度 BF16 微调的模型的性能相当,而使用 FP8 的训练速度还快 27%。此外,FP8 混合精度在 RLHF 方面也展现出了巨大的潜力,该过程需要在训练期间加载多个模型。通过在训练中使用 FP8,流行的 RLHF 框架 AlpacaFarm 可将模型权重减少 46%,将优化器状态的内存消耗减少 62%。这能进一步展现新提出的 FP8 低精度训练框架的多功能性和适应性。
他们也进行了消融实验,验证了各组件的有效性。
可预见,FP8 低精度训练将成为未来大模型研发的新基建。
更多细节请参见原论文。
好了,关于用FP8训练大模型有多香?微软:比BF16快64%,省42%内存就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “精度”用FP8训练大模型有多香?微软:比BF16快64%,省42%内存
- “中牟县”不低于50亿元,郑州市产业母基金专项支持汽车产业链
- “宁波”宁波联通深耕5G精品网建设 赋能智慧新文旅保障游客放心出行
- “新能源”新能源汽车、水力发电、智慧码头……中国“智”造奏响新时代的丝路乐章!
- “美容师”鸿茅药业举办“冬日暖阳送健康 守护城市美容师”公益活动
- “嫌疑人”女子银行取钱遭持刀抢劫600元,“精致小伙”获刑4年:生活奢侈,经常混迹夜场
- “一言”百度文心一言推出会员模式:定价59.9元/月,仅可为非商业目的使用
- “红星”四川宜宾辅警江边遛娃听到呼救:立即将孩子交给路人,跳江救起16岁落水少年
- “聚苯乙烯”首次证实:微塑料能引发机体慢性炎症反应
- “马修”《老友记》六人已少一人,剩余五人首度集体发声:彻底崩溃
- “模型”vivo发布蓝心大模型,手机端运行且开源,自研系统亮相
- “时空”高德发布产业融合大模型“云睿”,面向多行业提供AIGC融合解决方案
- “专业版”百度推出文心一言专业版 用户可继续免费使用基础版
- “医疗”可辅助医生诊断:中山医院联合光启慧语发布医疗大模型
- “模型”万万没想到,ChatGPT参数只有200亿?
- “模型”独家 | GPT-4、Midjourney之外,谭平创业团队要造一个3D基础模型
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了








