“模型”给爆火的Llama 2划重点,Huggingface机器学习科学家写了篇分析文章
今天,很高兴为大家分享来自机器之心Pro的给爆火的Llama 2划重点,Huggingface机器学习科学家写了篇分析文章,如果您对给爆火的Llama 2划重点,Huggingface机器学习科学家写了篇分析文章感兴趣,请往下看。
选自NATHAN LAMBERT博客
机器之心编译
编辑:陈萍
Llama 2 刚刚发布没几天,围绕它的分析文章就已经出来了。
Meta 发布的免费可商用版本 Llama 2 刷屏整个网络。
此前,Llama 1 版本因为开源协议问题,一直不可免费商用。现在,随着 Llama 2 的发布,这一限制正式被打破。
Llama 2 模型系列包含 70 亿、130 亿和 700 亿三种模型,此外 Meta 还训练了一个 340 亿参数变体,但并没有发布,只在技术报告中提到了。
发布之初, Llama -2-70B-Chat 迅速登顶 Hugging Face 的 Open LLM Leaderboard。
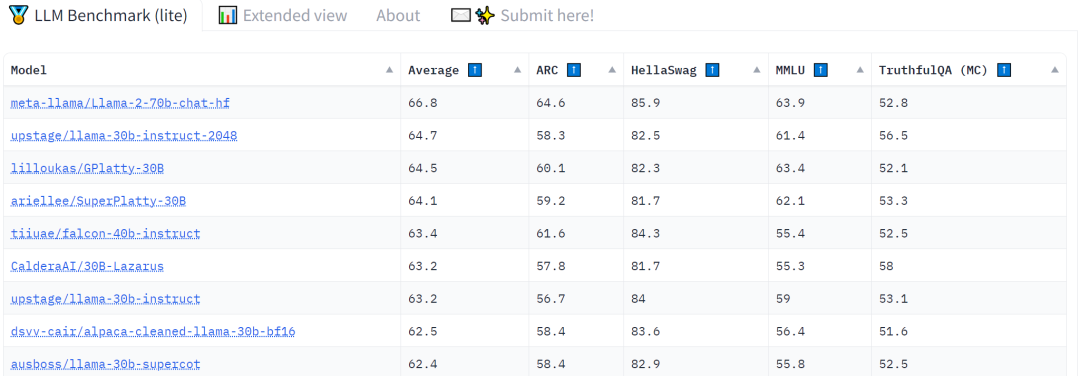
可以说, Llama 2 是 Llama 1 模型的延续,不论是在数据质量、训练技术、性能评估、安全训练等方面都进行了实质性的技术扩展。
Meta 的这一发布,对于开源来说是一个巨大的飞跃,但对于闭源提供商来说却是一个巨大的打击,因为这个模型提供了更高的可定制性和更低的成本。
相信大家很想了解关于 Llama 2 的更多信息,除了官方公开的技术资料外,来自 Huggingface 的机器学习科学家 Nathan Lambert 根据论文内容也为我们整理了一份详细的资料,文章还融入了他自己的见解。
Llama 2 论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Nathan Lambert 从以下几个方面展开介绍:
模型:Meta 发布了多个模型,70 亿、130 亿、700 亿、340 亿参数变体 ,以及 Llama 2-Chat。Meta 将预训练语料库的大小增加了 40%,将模型的上下文长度增加了一倍至 4k,并采用了分组查询注意力机制;(注:Llama 2 是否可被定义为「开源模型」目前还存在争议,作者在最新的更正版本中认为它不是。)
性能:Llama 2 模型系列除了在大多数基准测试中优于开源模型之外,根据 Meta 对有用性和安全性的人工评估,它或许也是闭源模型的合适替代品;
成本:Meta 动用了巨大的预算,预计该项目的总成本将在2000万至4500万美元之间。单就数据来说,如果按市场价格计算,准备偏好数据花费约为 800 万美元,数据团队非常庞大,由此看来 Meta 开发通用模型的赌注非常大;
团队组织:一些关于 Meta AI 组织变化的迹象,这个团队和 Yann Lecun 以及原始 FAIR 成员似乎不同;
代码、数学以及推理:文中对代码数据和 RLHF 的讨论并不多;
多回合一致性(Multi-turn consistency):文中提出了一种新技术 ——Ghost Attention (GAtt),这种方法有助于控制多个回合的对话流;
奖励模型:研究使用两种奖励模型来达到安全性 - 有用性的权衡;
RLHF 过程:本文采用两阶段的 RLHF 方法,首先使用拒绝抽样(Rejection Sampling),然后结合近端策略优化(Proximal Policy Optimization,PPO)进行拒绝抽样 + 近端策略优化处理。论文还指出,RLHF 非常重要,且 LLM 出色的写作能力,基本上是由 RLHF 驱动的;
安全和危害性评估:论文用大量篇幅介绍了安全评估(几乎占据论文一半)、上下文蒸馏以及 RLHF 用于安全目的;
许可:该模型可用于商业用途,除非你的产品月活用户数 >= 7 亿,需要填写表格以获取访问权限。
Nathan Lambert 猜测,Llama 2 很可能已经训练了几个月,他预计下一个版本也正在酝酿之中。
基础模型
Llama 2 在架构和其他方面与原始 Llama 非常相似,但 Llama 2 增加了上下文长度并采用了分组查询注意力(GQA,grouped-query attention)机制。Llama 2 大多数更改都是针对数据和训练过程的。增加上下文长度可以满足聊天的可用性要求,分组查询注意力机制可以提高推理速度。
Llama 2 的训练语料库包含了来自公开可用资源的混合数据,并且不包括 Meta 产品或服务相关的数据。此次,Meta 努力删除了包含大量个人隐私信息网站的数据。此外,Llama 2 预训练模型是在 2 万亿的 token 上训练的,这样可以在性能和成本之间取得良好的平衡。
Meta 公开的论文大部分内容是关于评估和微调的,而不是重新创建一个强大的基础模型。这一做法可能会强化 Meta 作为开源大语言模型领导者的地位。
下图为 Llama 2-Chat 的训练 pipeline。Meta 在偏好数据上训练奖励模型,然后用强化学习对其进行优化,以提高模型质量。

偏好数据
Nathan Lambert 表示,通过 Meta 发布的论文,他证实了一个谣言,即 Meta 赞同奖励模型是 RLHF 的关键,也是模型的关键。为了获得一个好的奖励模型,Meta 不得不努力收集偏好数据,这些数据远远超过了开源社区目前使用的数据量。
关于数据的更多信息如下:
Meta 收集了大量的二元比较数据,如「显著更好、更好、稍微更好」,而不是其他更复杂的反馈数据类型;
Meta 将数据收集的重点放在有用性和安全性上,在数据收集时对每个数据供应商使用单独的指导方针;
Meta 为收集的数据添加了额外的安全元数据(safety metadata),以显示在每个回合中模型的哪些响应是安全的;
Meta 采用了迭代式的数据收集方法:人工注释以每周一批的方式进行收集。随着收集到的偏好数据增多,奖励模型也得到了改善。
Nathan Lambert 预测,假设供应商收费接近市场价格,那么 Meta 这次发布仅数据成本可能超过 800 万美元。下表总结了 Meta 长期以来收集到的奖励建模数据,并将其与多个开源偏好数据集进行了对比。
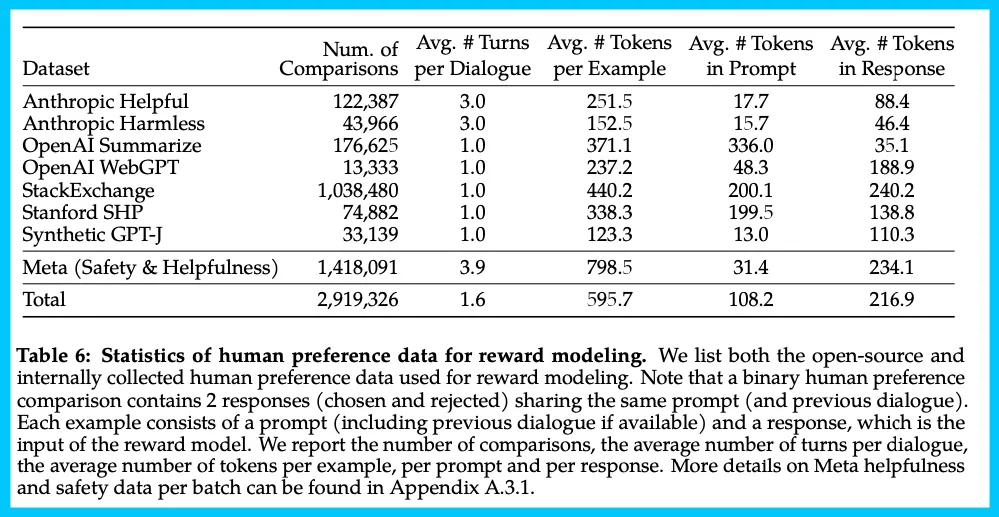
奖励模型
关于奖励模型有两个重要细节:
两个奖励模型被用来区分有用性和安全性的目标上;
奖励模型在迭代部署时,以确定所需的偏好数据量。
首先,论文指出他们训练了两个独立的奖励模型,一个针对有用性进行优化(称为 Helpfulness RM),另一个针对安全性进行优化(称为 Safety RM)。这两个模型都基于基础语言模型构建,用线性回归层替代了标准语言模型的头部。他们没有指明模型来自哪个 checkpoint,而是使用最新的聊天模型来最小化 RLHF 训练中的分布不匹配。
在这个过程中还有一些值得注意的技术细节:
在没有详细解释为什么需要的情况下,Meta 仍然保留了一些 Anthropic 的无害数据;
只训练了一个 epoch,这是为了避免奖励模型容易出现过拟合;
奖励模型的平均准确率仍然只在 65-70%,但当标注者的偏好一致性较强时,准确率可达 80-90%。
下图展示了奖励模型的准确性是如何随着时间的推移而变化的。
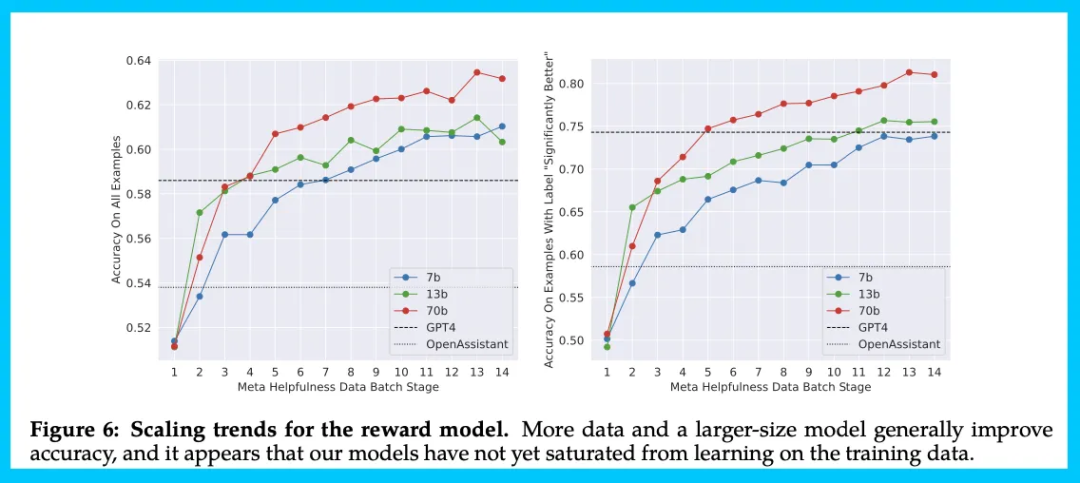
RLHF 和微调
Meta 展示了他们如何利用 RLHF 来有意义地改进模型。他们迭代的训练了 5 个 RLHF 版本,RLHF- V1,…, RLHF-V5。

从一开始,Meta 就指出了数据质量对模型的重要性。
Meta 在论文中表示:「Quality Is All You Need。我们可以从不同的来源获取第三方 SFT( Supervised Fine-Tuning )数据,但我们发现很多数据缺乏多样性,并且质量也不高,尤其是将 LLM 模型与对话式指令进行对齐的数据。我们将来自第三方的数据集示例置于一旁,并使用少量的、但质量更高的、来自我们自己供应商的注释示例,结果性能显著改善。」
Meta 发现,注释数达到数万个的 SFT 足以实现高质量的结果。因而,Meta 在收集了总共 27540 个注释后停止了 SFT 的注释工作。
Meta 还观察到,不同的注释平台和供应商提供的数据可能会导致下游模型性能的不同,这表明即使是供应商注释的数据,后续检查也是很重要的。Meta 为了验证数据质量,他们仔细检查了一组包含 180 个示例的数据,并将人工提供的注释与模型通过人工审查生成的样本进行比较。
数据质量建立起来后,Meta 开始专注于强化学习组件:
Meta 在论文中表示:「强化学习在我们的研究中表现非常高效,尤其是考虑到其成本和时间效率。我们的研究结果强调了 RLHF 成功的关键因素在于它在整个注释过程中促进了人类和 LLM 之间的协同作用。」
Meta 的这一表述非常有趣,因为这是第一篇明确指出 RLHF 在本质上提高了模型性能上限的论文,而其他研究团队则认为 RLHF 很重要,但只将其视为一种安全工具。
Nathan Lambert 认为,高效的 RLHF 需要至少一个中等规模的团队。一个由 1-3 人组成的团队可以发布一个优秀的指令模型,但他认为这种 RLHF 至少需要 6-10 人的团队。随着时间的推移,这个数字可能会减少。
评估
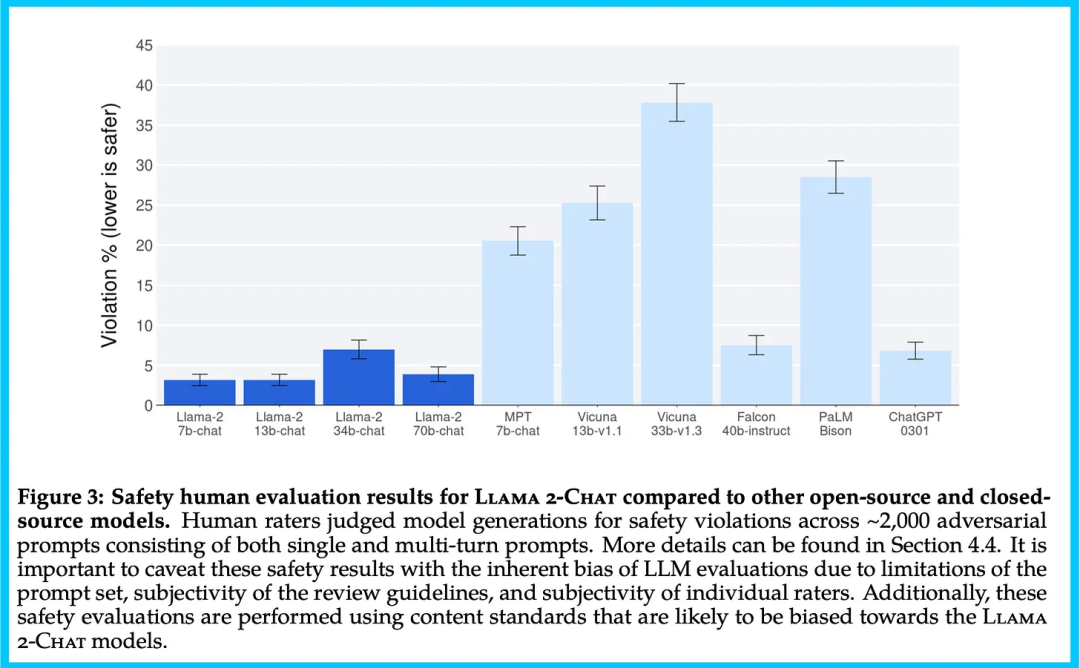
论文从很多方面评估了他们的模型。下图将 Llama 2-Chat 模型的人类评估结果与开源和闭源模型进行比较:结果显示,Llama 2-Chat 模型在单回合和多回合提示上均显著优于开源模型。特别是,Llama 2-Chat 7B 模型在 60% 的提示上胜过 MPT-7B-chat 模型。而 Llama 2-Chat 34B 模型在与容量相当的 Vicuna-33B 和 Falcon 40B 模型对战中,总体胜率超过 75%。
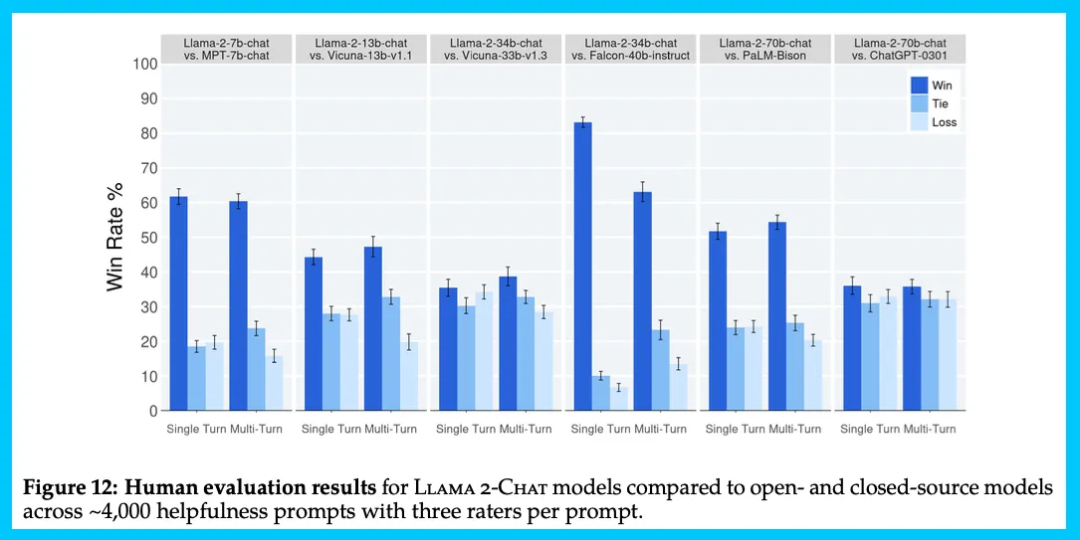 图 11 报告了不同的 SFT 和 RLHF 版本在安全性和有用性两个维度上的进展:
图 11 报告了不同的 SFT 和 RLHF 版本在安全性和有用性两个维度上的进展: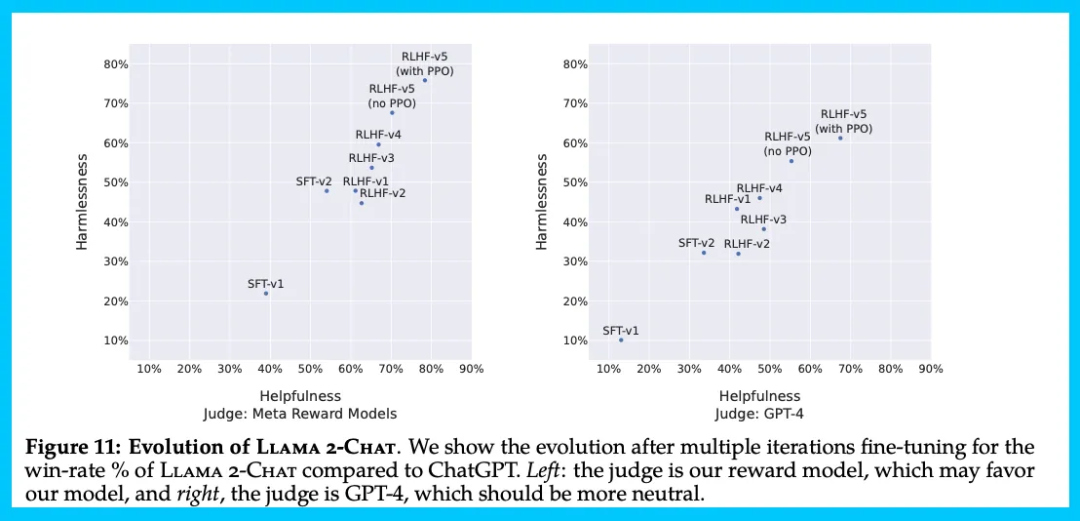
以上就是 NATHAN LAMBERT 博客的主要内容,后续关于 Llama 2 的分析文章他还在准备中,感兴趣的读者可以关注一下。
原文链接:https://www.interconnects.ai/p/llama-2-from-meta?sd=pf
好了,关于给爆火的Llama 2划重点,Huggingface机器学习科学家写了篇分析文章就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “西湖”西湖大学成立5周年,施一公:做创新的守护者是使命也是未来
- “儿子”妈妈将50余万“读书钱”存儿子名下,19岁儿子取出转给女友,妈妈无奈起诉追回
- “力学”王博已任大连理工大学副校长
- “说了”云朵的话语,心灵的方剂 ——读周实《有些话语好像云朵》
- “超新星”云南天文台发现Ia型超新星前身星候选体
- “科幻”和成都和教育,一起遇见未来!两份重要“科幻教育”名单公布
- “红星”梁静茹南京演唱会再现“柱子票” 主办方:临时布置追光灯,正与观众沟通
- “导盲犬”视障女子自曝带导盲犬进公园遭保安阻拦 公园方:天色较晚不知其实情,沟通后已放行
- “小行星”首次!我国计划实施近地小行星防御任务
- “肿瘤”科学家揭示肿瘤免疫逃逸新机制,鉴定三个癌症生存相关因子,为肿瘤免疫治疗注入新动力
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “炮车”评论丨雾炮车昼夜狂喷监测点?斩断伸向环境监测数据作假之“手”
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等
- “数据”奇富科技知微实验室揭秘黑市数据交易链条
- “融资”国内AI大模型赛道火热,大厂积极跟投布局









