“模型”采访高通Ziad Asghar:混合 AI 将“隐形”颠覆人机交互
今天,很高兴为大家分享来自DeepTech深科技的采访高通Ziad Asghar:混合 AI 将“隐形”颠覆人机交互,如果您对采访高通Ziad Asghar:混合 AI 将“隐形”颠覆人机交互感兴趣,请往下看。
来源:DeepTech深科技
 图:高通技术公司产品管理高级副总裁兼 AI 负责人 Ziad Asghar 在 WAIC丨来源:高通
图:高通技术公司产品管理高级副总裁兼 AI 负责人 Ziad Asghar 在 WAIC丨来源:高通在上周的世界人工智能大会(WAIC)期间走进上海世博展览中心,你会以为整个世界都用大模型重做了一遍。连续 3 天,上百场的论坛和研讨会,每个人都在谈论 GPT、大模型和其下游的无数应用,如此高密度的信息轰炸让即便是 AI 最狂热的拥趸也会略感疲劳。不过,高通和他们带来的混合 AI 仿佛一阵新风,讲了一个让人耳目一新的故事,要把 AI 大模型真正放到我们每个人的“手”中。
在高通技术公司产品管理高级副总裁兼 AI 负责人 Ziad Asghar 的演示中,他提出在云端和终端进行分布式处理的混合 AI 才是 AI 的未来,在成本、能耗、性能、隐私安全和个性化等方面皆优于单一架构的云端大模型,也就是现在的主流范式。展示中,我们看到当下流行的文生图 AI 模型 Stable Diffusion 完全独立地在一台搭载了第二代骁龙 8 平台的智能手机上高效运行,全程不联网且在 15 秒内通过 20 步推理生成了一张 512*512 像素的图像;而更大参数量的图生图模型 ControlNet(15 亿参数)也同样在手机上实现了流畅运行。

图:Stable Diffusion 在第二代骁龙 8 平台上生成的图片,提示词:“穿盔甲超级可爱的毛绒绒猫战士、逼真、4K、超细节、V-Ray 渲染、虚幻引擎” 来源:高通
作为移动平台领导者,Ziad 相信高通在推动终端侧 AI 发展方面独具优势,而混合 AI 将为当下火热的 AI 大模型带来真正的规模化扩展和普及。我们看到,人人都拥有属于自己的大模型的前景十分诱人,但在那之前,人机交互方式的变革和 AI 指数级的扩张也势必会遭遇不小的挑战。为此,我们采访了 Ziad Asghar,以图一窥这一宏大愿景中的些许细节。

“AI 原住民”的探索
DeepTech:
高通深耕 AI 已经超过 15 年,在芯片层面,最早可以追溯到 10 年前的 Zeroth 处理器和 SNN 架构,而在今年 3 月巴塞罗那世界移动通信大会(MWC)期间首次亮相的全球首例终端侧 Stable Diffusion 演示更令人印象深刻。从云端到终端,高通“驯化”这一扩散模型花了多长时间?
Ziad Asghar:
从我们的角度来看,我们从未停止将模型部署到终端设备上的努力。比如,AI 在音视频上已经应用多年,你的手机能在昏暗的房间里拍摄到清晰的画面就是 AI 的功劳,而所有这些都是我们长期以来一直在开发的。
在这个过程中,我们构建并积累了大量 AI 原生的工具、资产和软硬件。不过,我们真正与众不同的地方在模型的 AIMET 量化上。一般情况下,人们都试图用浮点运算去进行 AI 模型推理,原因很简单——大模型的预训练就是这样做的。但我们一直认为,浮点运算会带来过高的功耗,并坚持采用基于整数的、位数更少的处理方式,这给我们带来了一个独特的优势。使用自适应舍入(AdaRound)技术,我们可以将大模型从 FP32 压缩为 INT4,却在精度上几乎没有损失。
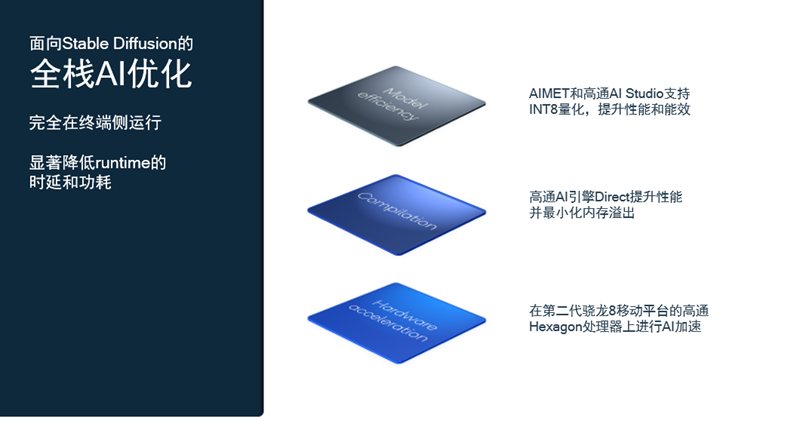 图:高通针对 Stable Diffusion 的全栈 AI 优化丨来源:高通
图:高通针对 Stable Diffusion 的全栈 AI 优化丨来源:高通所以,在遇到 Stable Diffusion 的时候,我们实际上已经研究了两三年生成式 AI 了,早已准备好了高通 AI 模型增效工具包、高通 AI 软件栈和高通 AI 引擎等一系列先进工具和软硬件。事实上,在 Stable Diffusion 开源之后,我们只用了不到一个月的时间就完成了模型 AIMET 量化,实现了在骁龙平台上的高速运行。这在 MWC 上引起了挺大的反响,因为此前没有人能做到在小小的手机上运行大模型。不过我认为,这才是真正的能让每个人都用上 AI 的办法。

掌上大模型的挑战
DeepTech:
终端侧 AI 的一大优势就在于对周边感知数据的利用,不过要做到这一点需要部署更多模态的 AI 模型,而目前已知的多模态 AI 大模型参数量都非常大,在终端侧实现难度不小。您认为我们会很快看到多模态在终端侧的实现吗?
Ziad Asghar:
我认为这将很快能够实现,因为其实并不存在什么实质性的阻碍。我在演讲中展示了 Stable Diffusion 和 ControlNet 两个模型,分别是文生图和图生图,从某种意义上来说已经是多模态的了,不是吗?OpenAI 的 GPT-3.5 模型有 1750 亿参数,而 Meta 的 LLaMa 模型系列中最大的才 650 亿,却能实现更好的效果。因此,我认为只要模型训练中使用了合适的数据,多模态模型可以不做得那么大,而且已经在迅速变小了。我的观点是,更多的优秀多模态大模型将会很快出现,而它们在终端侧设备上的良好运行只是时间问题。
到目前为止,我们使用的都是开源模型,同时也在高通内部进行很多研究。我们的工作重点不是全面完整的模型训练,而是在获取模型的基础上进行微调,比如使用 LoRA 模型等技术让终端侧 AI 的体验更好,为每个人量身定制自己的 AI,这也是我本人最为关注的方向。
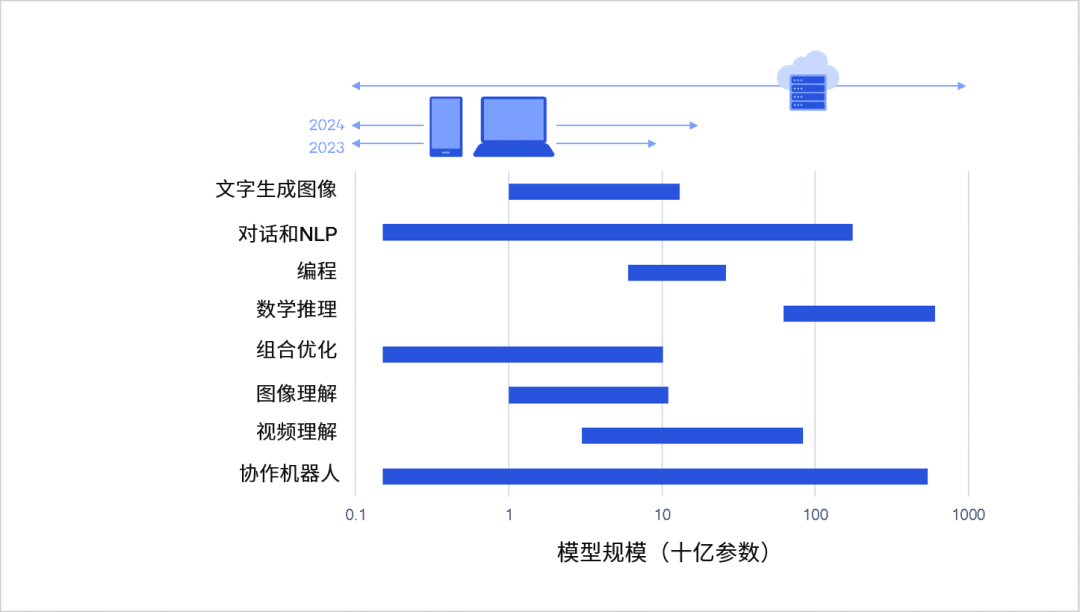 图:数量可观的生成式 AI 模型将可从云端分流到终端上运行丨来源:《混合 AI 是 AI 的未来》白皮书
图:数量可观的生成式 AI 模型将可从云端分流到终端上运行丨来源:《混合 AI 是 AI 的未来》白皮书DeepTech:
您谈到了量身定制,不过要让智能手机成为真正的个人助理,意味着终端侧 AI 大模型需要在运行过程中“记住”主人的偏好和使用习惯。当前,以 GPT 为代表的大模型支持的 token 数在不断增加,却仍是有限的,也就是说 AI 最终会“失忆”。就混合 AI 来说,我们要如何应对这个问题?
Ziad Asghar:
这正是我们谈到的终端侧模型微调所要实现的事情,即一个更加个性化的虚拟助理,这也是终端侧生成式人工智能所许诺的愿景。“云”并不了解你,也永远不可能了解你,退一万步说,如果模型在收集了你的个人信息后回到云端重新训练、调整,就势必会出现隐私和安全问题,而终端侧 AI 就没有这个问题,因为数据和模型都不会离开本地。
终端侧 AI 能做到的是在用户使用的过程中慢慢地、逐渐地学习用户的习惯、癖好和特殊性,比如一个人每天早上都会去晨跑等,并逐步对模型进行某种程度的微调,以至于当你要求它给你订餐的时候,它能知道你喜欢什么样的食物,并为你挑选。
当然还有另外一种方法,就是在模型之上部署一个个性化定制的治理层,拥有比大模型本身更高的权限,所有的生成工作都在预设之下进行。当下以 GPT 为代表的大模型的“幻觉”问题始终难以根除,这种方法也是人们提出的其中一个解决思路。从某种意义上来说,它不仅能解决“幻觉”问题,也能解决“失忆”问题。
重点是,用户体验必须是自然的、无缝的乃至无感的,方能真正实现 AI 个人助理。
DeepTech:
如今,终端侧在混合 AI 架构下的角色更多的是分担云端大模型的算力,主要承担的是模型推理的部分。而要实现真正的定制、个性化 AI 助理,或许需要支持每一位用户自己进行训练。未来,终端侧 AI 是否将向着一边预训练、一边推理的方向发展?
Ziad Asghar:
这个目前还没有出现,但我认为很有可能。当下,我们可以设置多大的模型和运算在终端侧运行也会因设备而异,比如汽车的 AI 算力比头显要强得多,那么就可以承担更多的运算和更大的模型规模。同时,我们还可以让同一个模型不同规模的版本在终端侧和云端同时运行,也就是在终端侧运行轻量版模型时,在云端并行处理完整模型的多个标记(token),并在需要时更正终端侧的处理结果,这样做的好处也显而易见,可以极大地缓解云端大模型的能耗问题等。
未来,终端侧 AI 还可能作为额外的(分布式)算力中心,对云端算力进行补充,承担大量的工作荷载。
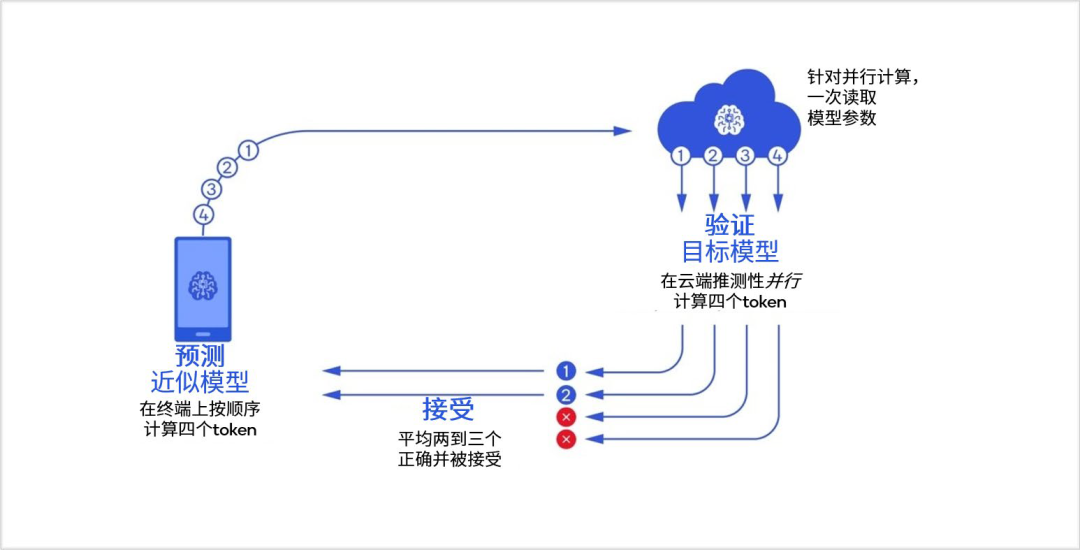 图:协同处理混合 AI 的四个 token 推测性解码示例丨来源:《混合 AI 是 AI 的未来》白皮书
图:协同处理混合 AI 的四个 token 推测性解码示例丨来源:《混合 AI 是 AI 的未来》白皮书
混合 AI 的“云终”共建
DeepTech:
您之前强调了好的用户体验,我也认为它非常重要。在混合 AI 的架构下,终端侧 AI 和云端 AI 必须通力合作才能实现这一点,而终端在模型工作量上的分配策略将直接影响用户体验。在您看来,这种体验会是什么样的?我们需要不断在付费(云端)和免费(终端)之间选“是”或“否”吗?
Ziad Asghar:
(笑)那样是根本行不通的,用户体验非常重要,混合 AI 必须提供一个无缝的、非常好的体验,否则人们就会试用一两次然后就弃置一旁了,而好的体验才能让它真正推广、普及下去。我认为,这种无缝的体验必须由应用程序服务提供商来实现。我们知道如今大模型的搜索成本是传统搜索引擎的 10 倍,任何云端 AI 处理的请求都相当贵。对于应用程序提供商来说,全部运算在云端进行意味着极高的成本,而反过来在终端设备上运行则几乎没有成本,而他们需要在两者之间找到这个平衡。
对用户来说,用户付费购买的是应用层面的服务,理想情况下甚至不需要知道请求是在哪里处理的,一个优秀的应用程序应该能够做到这一点。
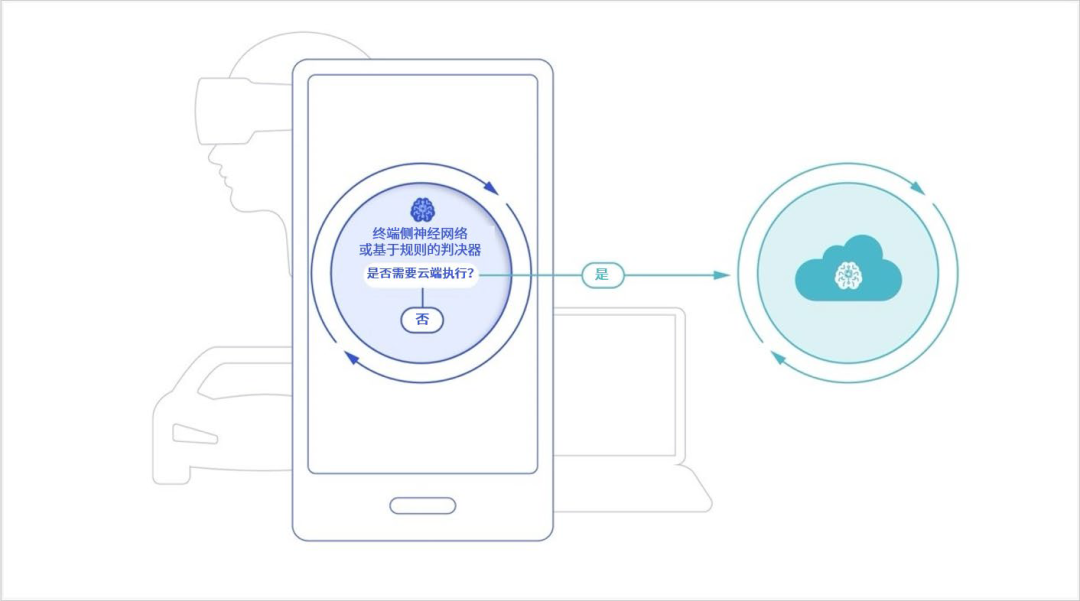 图:终端侧 AI 与云端 AI 之间的分流丨来源:《混合 AI 是 AI 的未来》白皮书
图:终端侧 AI 与云端 AI 之间的分流丨来源:《混合 AI 是 AI 的未来》白皮书DeepTech:
是的,当前流行的云端 AI 大模型训练、运营成本都极其高昂,因此也都面临着商业化的问题,而终端侧 AI 的模型源自于他们。高通是终端侧的龙头企业,也是混合 AI 生态的领袖。从商业角度来看,您认为应该如何制定分配策略,建立互利共赢机制,从而让云端大模型服务商也能获利,并且与终端一起推动产业生态发展?
Ziad Asghar:
在我看来,其实两者之间不存在冲突。当下我们能看到的是,首先许多模型正变得越来越大,其后果就是单个查询请求的成本在不断升高;其次,现在已经出现了几十个生成式 AI 的应用程序,且还在增加;第三,数十亿的用户如今想要用上这些此前没有的 AIGC 功能。我的观点是,一旦每个人都真正开始使用生成式 AI 时,云端是没有能力提供这样大规模的服务的。从可持续发展的角度来看,每个 GPU 单元都需要数百瓦的电力支撑,云端算力想要继续增长的代价极大,所以我认为云端服务商其实是希望终端设备能够分担部分负载、算力和功耗的。
在我看来,云端服务商仍然可以通过应用程序等方式进行商业变现,他们为用户提供服务,并在应用程序设计上制定工作量在云端和终端之间的分配策略,就比如手机上的 ChatGPT 应用,未来可能实现由手机本身来分摊一部分算力。我相信,这将帮助云端 AI 服务商们实现进一步的规模化扩张。
当下,我们正在与很多合作伙伴商讨相关细节。未来几个月,我们将能在终端侧支持 100 亿的模型参数量,比如 LLaMa 模型当前就有一个 70 亿参数的版本和一个 130 亿参数的版本,在终端上的运行将不成问题,大部分的运算会在本地进行。我相信,这才是让每个人都能从 AI 中获益的真正方式。
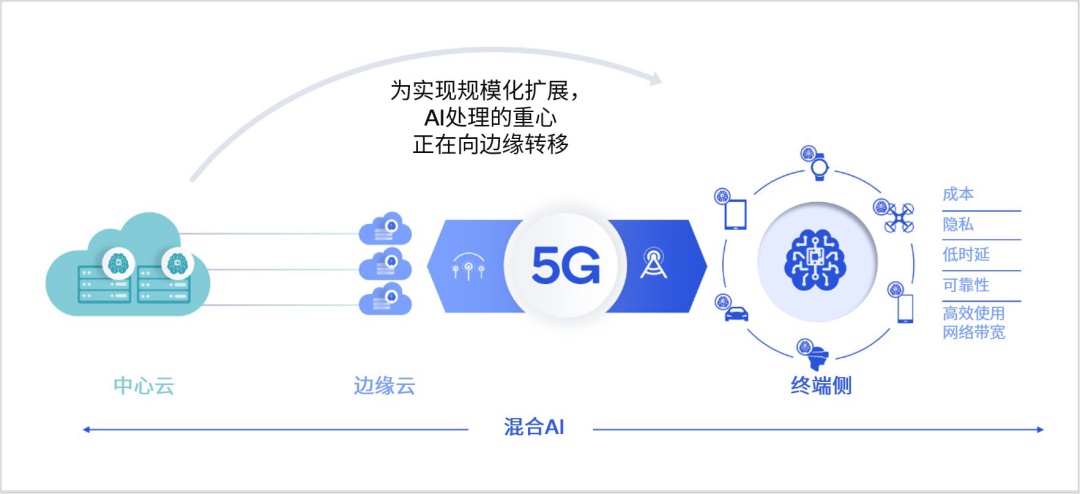 图:AI 处理的重心正在向边缘转移丨来源:《混合 AI 是 AI 的未来》白皮书
图:AI 处理的重心正在向边缘转移丨来源:《混合 AI 是 AI 的未来》白皮书DeepTech:
AIGC 正在改变人类与计算机交互的方式,而混合 AI 无疑将把这个范围进一步扩大。不过就交互而言,各个国家和地区在文化、社会等层面存在很大差异,高通如何看待在中国的本地化工作以及这种差异?
Ziad Asghar:
毫无疑问,混合 AI 将重塑人机交互的方式。你很可能在各个方面都只分别需要一个应用就能搞定所有,比如生产力一个应用,娱乐一个应用等,然后再用一个 AI 个人助理来整合、统筹所有这些事情,这会是一场极具颠覆性的变革。
确实,不同文化之间的差异决定了不同地区的交互方式很可能并不相同,我认为混合 AI 在中国和美国的最终解决方案就会大相径庭,原因也很简单,比如微信的使用就与美国很多社交工具完全不一样,每个国家和地区可能都会需求更加适合、更加个性化的方案。
就中国而言,我觉得中国人使用终端侧设备的频率更高,方式也比较不一样,自然也需要一种独特的解决方案。我相信,一个兼容并包的“超级 App”出现在中国的可能性更大。
DeepTech:
混合 AI 有望对当下火热的大模型进行非常激进的规模化扩展,想象力几乎没有上限,或许相比当年移动互联网的强势崛起更甚。最后,您能否为我们描绘一下混合 AI 未来三到五年的终极应用场景?
Ziad Asghar:
我相信在五年内,混合 AI 将彻底改变我们的生活方式。以智能汽车为例,当下我们会跟汽车说“导航去 XX 地点”,未来在生成式 AI 和车载传感器的加持下,我们可以与车对话,告诉它我想去机场,但在那之前还想找个离机场不太远的高级餐厅吃顿好的,同时还打算沿途买杯咖啡,而你的车应该能够帮你做到所有这些。
 图:终端侧生成式 AI 可用于先进驾驶辅助系统/自动驾驶丨来源:《混合 AI 是 AI 的未来》白皮书
图:终端侧生成式 AI 可用于先进驾驶辅助系统/自动驾驶丨来源:《混合 AI 是 AI 的未来》白皮书这是一种非常不同的交互方式。在你开车上班时,你的车将变成你真正的办公室;而在和家人一起出行时,它又变成了一个娱乐场所,智能手机也是一样。我们现在对手机说话是给它指令,而在它真正变成了掌中的虚拟个人助理之后,比方说你开会要迟到了,它就会知道你要迟到了,这时就不应该由你来给参加会议的人发消息告知,而是由手机来执行,安排会议也是一样。在我看来,这都是“低悬的果实”,其实应该马上就能实现的。
归根结底,我们与周围所有设备的连接、交互方式将发生翻天覆地的变化,变得更加无缝,但同时还应该更加“隐形”。在用到一项技术的时候,它应该能实现几乎无感,而不是时时都需要你有意识地去使用。这才是混合 AI 真正强大的地方。
好了,关于采访高通Ziad Asghar:混合 AI 将“隐形”颠覆人机交互就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “西湖”西湖大学成立5周年,施一公:做创新的守护者是使命也是未来
- “儿子”妈妈将50余万“读书钱”存儿子名下,19岁儿子取出转给女友,妈妈无奈起诉追回
- “力学”王博已任大连理工大学副校长
- “说了”云朵的话语,心灵的方剂 ——读周实《有些话语好像云朵》
- “超新星”云南天文台发现Ia型超新星前身星候选体
- “科幻”和成都和教育,一起遇见未来!两份重要“科幻教育”名单公布
- “红星”梁静茹南京演唱会再现“柱子票” 主办方:临时布置追光灯,正与观众沟通
- “导盲犬”视障女子自曝带导盲犬进公园遭保安阻拦 公园方:天色较晚不知其实情,沟通后已放行
- “小行星”首次!我国计划实施近地小行星防御任务
- “肿瘤”科学家揭示肿瘤免疫逃逸新机制,鉴定三个癌症生存相关因子,为肿瘤免疫治疗注入新动力
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等
- “融资”国内AI大模型赛道火热,大厂积极跟投布局
- “模型”在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了
- “图像”OpenAI终于Open一回:DALL-E 3论文公布、上线ChatGPT,作者一半是华人









