“是一个”速揽2500星,Andrej Karpathy重写了一份minGPT库
今天,很高兴为大家分享来自机器之心Pro的速揽2500星,Andrej Karpathy重写了一份minGPT库,如果您对速揽2500星,Andrej Karpathy重写了一份minGPT库感兴趣,请往下看。
机器之心报道
编辑:陈萍
时隔两年,GPT的Pytorch训练库minGPT迎来更新!
作为人工智能领域「暴力美学」的代表作,GPT 可谓是出尽风头,从诞生之初的 GPT 1.17 亿参数,一路狂飙到 GPT-3 1750 亿参数。随着 GPT-3 的发布,OpenAI 向社区开放了商业 API,鼓励大家使用 GPT-3 尝试更多的实验。然而,API 的使用需要申请,而且你的申请很有可能石沉大海。
为了让资源有限的研究者也能体验一把玩大模型的乐趣,前特斯拉 AI 负责人 Andrej Karpathy 基于 PyTorch,仅用 300 行左右的代码就写出了一个小型 GPT 训练库,并将其命名为 minGPT。这个 minGPT 能够进行加法运算和字符级的语言建模,而且准确率还不错。
时隔两年,minGPT 迎来更新,Karpathy 又上线新版本,并命名为 NanoGPT,该库用于训练和微调中型大小的 GPT。上线短短几天,狂揽 2.5K 星。
项目地址:https://github.com/karpathy/nanoGPT
在项目介绍中,Karpathy 这样写道:「NanoGPT 是用于训练和微调中型尺度 GPT 最简单、最快的库。是对 minGPT 的重写,因为 minGPT 太复杂了,以至于我都不愿意在使用它。NanoGPT 还在开发当中,当前致力于在 OpenWebText 数据集上重现 GPT-2。
NanoGPT 代码设计目标是简单易读,其中 train.py 是一个约 300 行的代码;model.py 是一个约 300 行的 GPT 模型定义,它可以选择从 OpenAI 加载 GPT-2 权重。」
为了呈现数据集,用户首先需要将一些文档 tokenize 为一个简单的 1D 索引数组。
$ cd data/openwebtext
$ python prepare.py
这将生成两个文件:train.bin 和 val.bin,每个文件都包含一个代表 GPT-2 BPE token id 的 uint16 字节原始序列。该训练脚本试图复制 OpenAI 提供的最小的 GPT-2 版本,即 124M 版本。
$ python train.py
假如你想使用 PyTorch 分布式数据并行(DDP)进行训练,请使用 torchrun 运行脚本。
$ torchrun --standalone --nproc_per_node=4 train.py
为了让代码更有效,用户也可以从模型中进行取样:
$ python sample.py
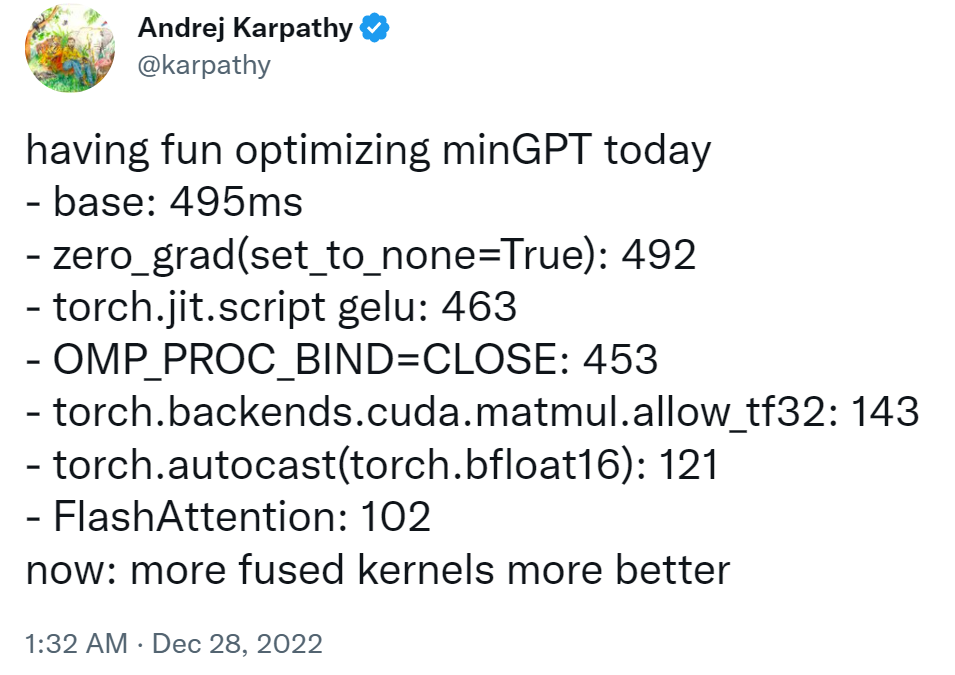
Karpathy 表示,该项目目前在 1 个 A100 40GB GPU 上一晚上的训练损失约为 3.74,在 4 个 GPU 上训练损失约为 3.60。在 8 x A100 40GB node 上进行 400,000 次迭代(约 1 天)atm 的训练降至 3.1。
至于如何在新文本上微调 GPT,用户可以访问 data/shakespeare 并查看 prepare.py。与 OpenWebText 不同,这将在几秒钟内运行。微调只需要很少的时间,例如在单个 GPU 上只需要几分钟。下面是运行微调的一个例子
$ python train.py config/finetune_shakespeare.py
项目一上线,已经有人开始尝试了:
想要尝试的小伙伴,可以参考原项目运行。
好了,关于速揽2500星,Andrej Karpathy重写了一份minGPT库就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “西湖”西湖大学成立5周年,施一公:做创新的守护者是使命也是未来
- “儿子”妈妈将50余万“读书钱”存儿子名下,19岁儿子取出转给女友,妈妈无奈起诉追回
- “力学”王博已任大连理工大学副校长
- “说了”云朵的话语,心灵的方剂 ——读周实《有些话语好像云朵》
- “超新星”云南天文台发现Ia型超新星前身星候选体
- “科幻”和成都和教育,一起遇见未来!两份重要“科幻教育”名单公布
- “红星”梁静茹南京演唱会再现“柱子票” 主办方:临时布置追光灯,正与观众沟通
- “导盲犬”视障女子自曝带导盲犬进公园遭保安阻拦 公园方:天色较晚不知其实情,沟通后已放行
- “小行星”首次!我国计划实施近地小行星防御任务
- “肿瘤”科学家揭示肿瘤免疫逃逸新机制,鉴定三个癌症生存相关因子,为肿瘤免疫治疗注入新动力
- “问答”ChatGPT重压下,Stack Overflow裁员28%,为自家生成式AI工具开源节流
- “癌症”田艳涛:提高癌症生存率的关键在于预防和早期发现
- “代码”程序员如何用ChatGPT编程?
- “代码”大模型写代码能力突飞猛进,北大团队提出结构化思维链SCoT
- “项目”狂揽13k star,开源版代码解释器登顶GitHub热榜,可本地运行、可访问互联网
- “代码”聚焦AIGC for Code,「硅心科技aiXcoder」完成A+轮融资,加速行业落地|早起看早期
- “代码”陶哲轩:用ChatGPT写代码太省时间了
- “代码”【清流Family】「硅心科技aiXcoder」完成A+轮融资,加速AIGC for Code行业落地
- “模型”迅速逼近ChatGPT!Llama 最新代码生成模型已经直追GPT-4了
- “代码”HuggingFace 推出企业 AI 代码助手 SafeCoder









