“数据”Transformer+强化学习,谷歌DeepMind让大模型成为机器人感知世界的大脑
今天,很高兴为大家分享来自机器之心Pro的Transformer+强化学习,谷歌DeepMind让大模型成为机器人感知世界的大脑,如果您对Transformer+强化学习,谷歌DeepMind让大模型成为机器人感知世界的大脑感兴趣,请往下看。
机器之心专栏
编辑:Panda
在开发机器人学习方法时,如果能整合大型多样化数据集,再组合使用强大的富有表现力的模型(如 Transformer),那么就有望开发出具备泛化能力且广泛适用的策略,从而让机器人能学会很好地处理各种不同的任务。比如说,这些策略可让机器人遵从自然语言指令,执行多阶段行为,适应各种不同环境和目标,甚至适用于不同的机器人形态。
但是,近期在机器人学习领域出现的强大模型都是使用监督学习方法训练得到的。因此,所得策略的性能表现受限于人类演示者提供高质量演示数据的程度。这种限制的原因有二。
第一,我们希望机器人系统能比人类远程操作者更加熟练,利用硬件的全部潜力来快速、流畅和可靠地完成任务。
第二,我们希望机器人系统能更擅长自动积累经验,而不是完全依赖高质量的演示。
从原理上看,强化学习能同时提供这两种能力。
近期出现了一些颇具潜力的进步,它们表明大规模机器人强化学习能在多种应用设置中取得成功,比如机器人抓取和堆叠、学习具有人类指定奖励的异构任务、学习多任务策略、学习以目标为条件的策略、机器人导航。但是,研究表明,如果使用强化学习来训练 Transformer 等能力强大的模型,则更难大规模地有效实例化。
近日,Google DeepMind 提出了 Q-Transformer,目标是将基于多样化真实世界数据集的大规模机器人学习与基于强大 Transformer 的现代策略架构结合起来。

论文:https://q-transformer.github.io/assets/q-transformer.pdf
项目:https://q-transformer.github.io/
虽然,从原理上看,直接用 Transformer 替代现有架构(ResNets 或更小的卷积神经网络)在概念上很简单,但要设计一种能有效利用这一架构的方案却非常困难。只有能使用大规模的多样化数据集时,大模型才能发挥效力 —— 小规模的范围狭窄的模型无需这样的能力,也不能从中受益。
尽管之前有研究通过仿真数据来创建这样的数据集,但最有代表性的数据还是来自真实世界。
因此,DeepMind 表示,这项研究关注的重点是通过离线强化学习使用 Transformer 并整合之前收集的大型数据集。
离线强化学习方法是使用之前已有的数据训练,目标是根据给定数据集推导出最有效的可能策略。当然,也可以使用额外自动收集的数据来增强这个数据集,但训练过程是与数据收集过程是分开的,这能为大规模机器人应用提供一个额外的工作流程。
在使用 Transformer 模型来实现强化学习方面,另一大问题是设计一个可以有效训练这种模型的强化学习系统。有效的离线强化学习方法通常是通过时间差更新来进行 Q 函数估计。由于 Transformer 建模的是离散的 token 序列,所以可以将 Q 函数估计问题转换成一个离散 token 序列建模问题,并为序列中的每个 token 设计一个合适的损失函数。
最简单朴素的对动作空间离散化的方法会导致动作基数呈指数爆炸,因此 DeepMind 采用的方法是按维度离散化方案,即动作空间的每个维度都被视为强化学习的一个独立的时间步骤。离散化中不同的 bin 对应于不同的动作。这种按维度离散化的方案让我们可以使用带有一个保守的正则化器简单离散动作 Q 学习方法来处理分布转变情况。
DeepMind 提出了一种专门的正则化器,其能最小化数据集中每个未被取用动作的值。研究表明:该方法既能学习范围狭窄的类似演示的数据,也能学习带有探索噪声的范围更广的数据。
最后,他们还采用了一种混合更新机制,其将蒙特卡洛和 n 步返回与时间差备份(temporal difference backups)组合到了一起。结果表明这种做法能提升基于 Transformer 的离线强化学习方法在大规模机器人学习问题上的表现。
总结起来,这项研究的主要贡献是 Q-Transformer,这是一种用于机器人离线强化学习的基于 Transformer 的架构,其对 Q 值使用了按维度的 token 化,并且已经可以用于大规模多样化机器人数据集,包括真实世界数据。图 1 总结了 Q-Transformer 的组件。

DeepMind 也进行了实验评估 —— 既有用于严格比较的仿真实验,也有用于实际验证的大规模真实世界实验;其中学习了大规模的基于文本的多任务策略,结果验证了 Q-Transformer 的有效性。
在真实世界实验中,他们使用的数据集包含 3.8 万个成功演示和 2 万个失败的自动收集的场景,这些数据是通过 13 台机器人在 700 多个任务上收集的。Q-Transformer 的表现优于之前提出的用于大规模机器人强化学习的架构,以及之前提出的 Decision Transformer 等基于 Transformer 的模型。
方法概览
为了使用 Transformer 来执行 Q 学习,DeepMind 的做法是应用动作空间的离散化和自回归。
要学习一个使用 TD 学习的 Q 函数,经典方法基于贝尔曼更新规则:

研究者对贝尔曼更新进行了修改,使之能为每个动作维度执行,做法是将问题的原始 MDP 转换成每个动作维度都被视为 Q 学习的一个步骤的 MDP。
具体来说,给定动作维度 d_A,新的贝尔曼更新规则为:
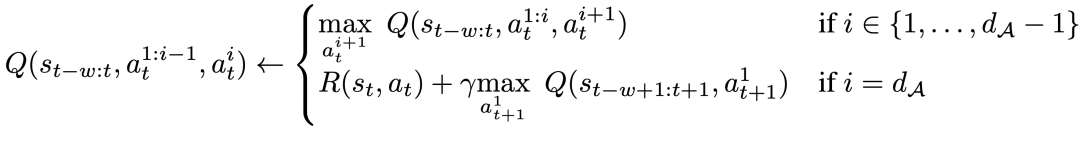
这意味着对于每个中间动作维度,要在给定相同状态的情况下最大化下一个动作维度,而对于最后一个动作维度,使用下一状态的第一个动作维度。这种分解能确保贝尔曼更新中的最大化依然易于处理,同时还能确保原始 MDP 问题仍可得到解决。
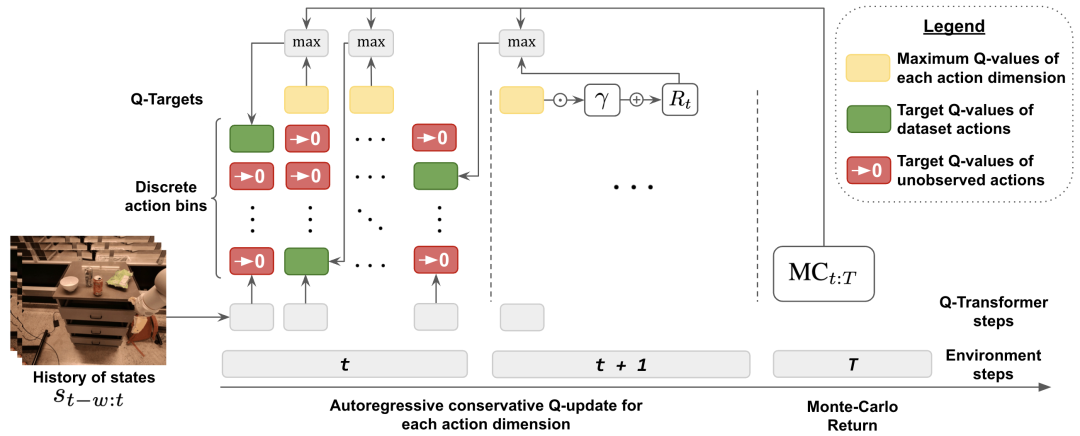
为了兼顾离线学习过程中的分布变化情况,DeepMind 还引入了一种简单的正则化技术,其是将未曾见过的动作的值降到最低。
为了加快学习速度,他们还使用了蒙特卡洛返回。其使用了对于给定事件片段(episode)的返回即用(return-to-go),也使用了可跳过按维度最大化的 n 步返回(n-step returns)。
实验结果
实验中,DeepMind 在一系列真实世界任务上评估了 Q-Transformer,同时还将每个任务的数据限制到仅包含 100 个人类演示。
除了演示之外,他们还添加了自动收集的失败事件片段,从而得到了一个数据集,其中包含来自演示的 3.8 万个正例和 2 万个自动收集的负例。
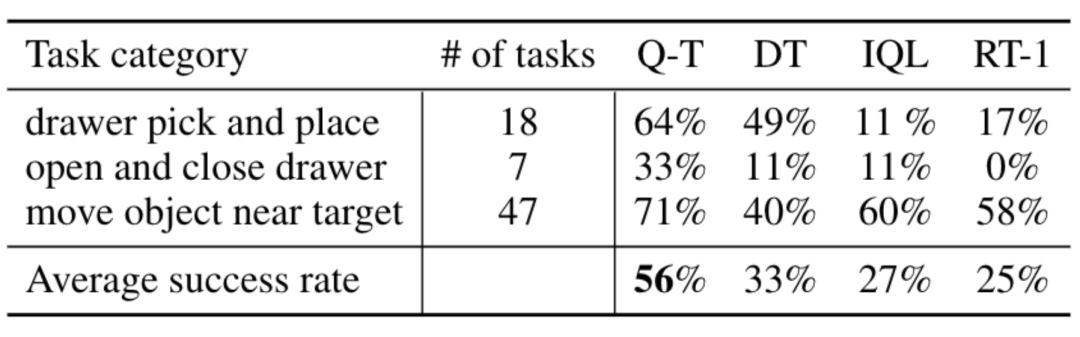

相比于 RT-1、IQL 和 Decision Transformer (DT) 等基准方法,Q-Transformer 可以有效地利用自动事件片段来显著提升其使用技能的能力,这些技能包括从抽屉里取放物品、将物体移动到目标附近、开关抽屉。
研究者还在一个高难度的模拟取物任务上对新提出的方法进行了测试 —— 在该任务中,仅有约 8% 的数据是正例,其余的都是充满噪声的负例。
在这个任务上,QT-Opt、IQL、AW-Opt 和 Q-Transformer 等 Q 学习方法的表现通常更好,因为它们可以通过动态程序规划利用负例来学习策略。
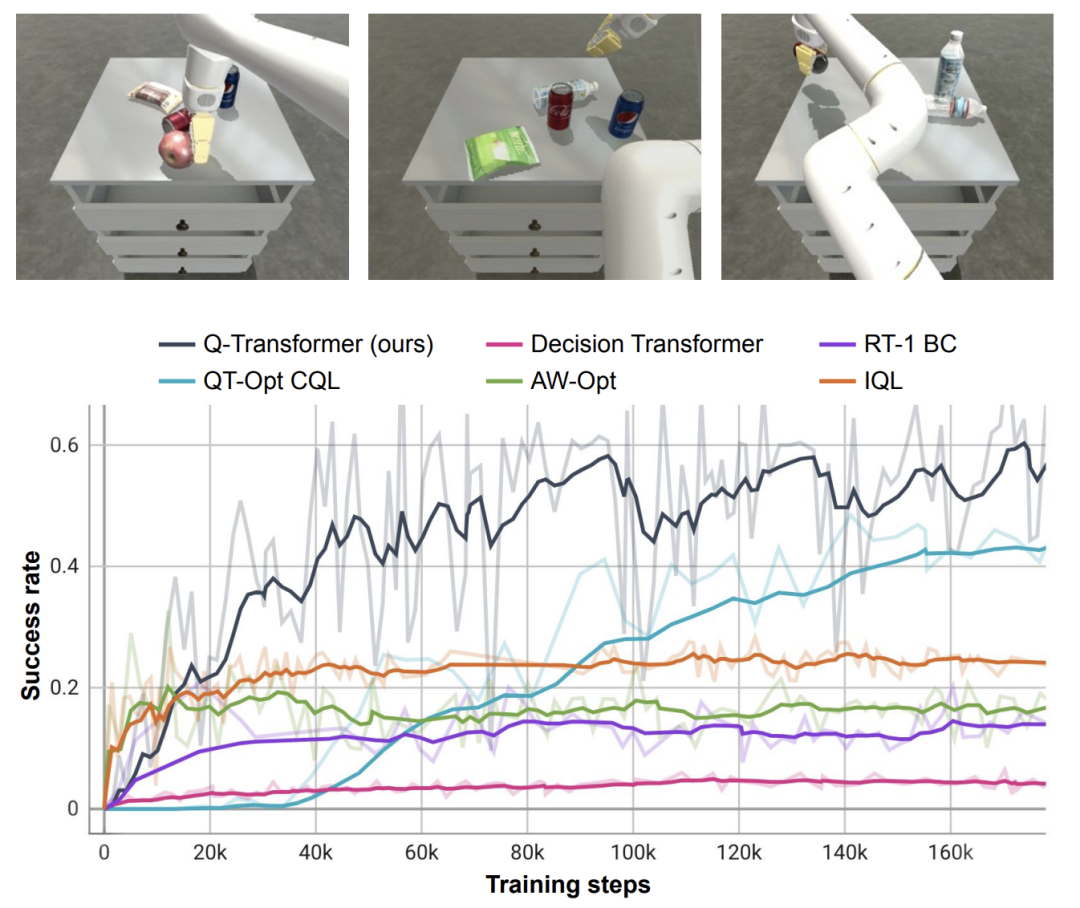
基于这个取物任务,研究者进行了消融实验,结果发现保守的正则化器和 MC 返回都对保持性能很重要。如果切换成 Softmax 正则化器,性能表现显著更差,因为这会将策略过于限制在数据分布中。这说明 DeepMind 这里选择的正则化器能更好地应对这个任务。
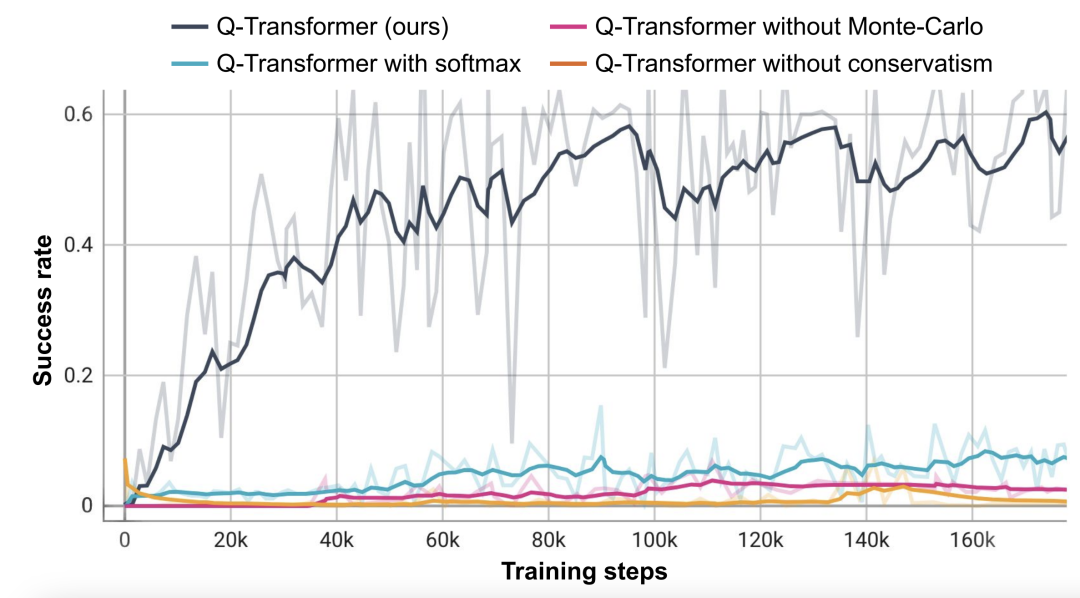
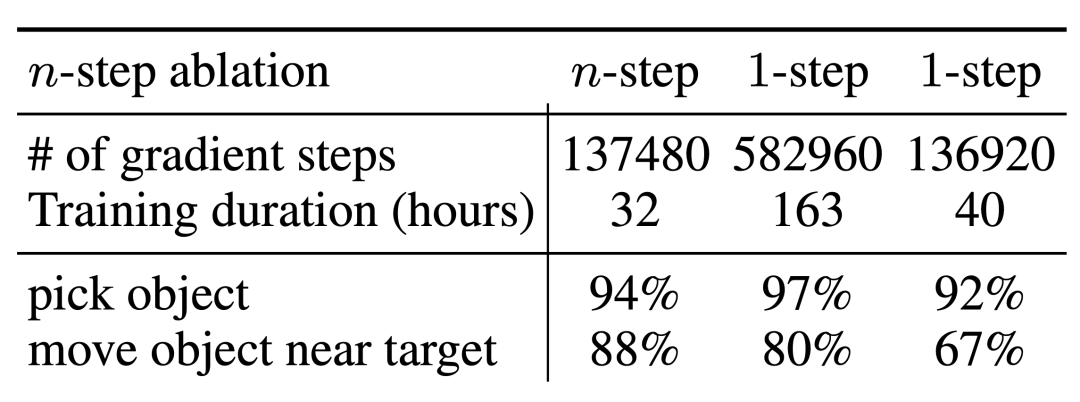
而他们对 n 步返回的消融实验则发现,尽管这会引入偏差,但这种方法却有助于在显著更少的梯度步骤内实现同等的高性能,能高效地处理许多问题。
研究者也尝试了在更大规模的数据集上运行 Q-Transformer—— 他们将正例的数量扩增至 11.5 万,负例的数量增至 18.5 万,得到了一个包含 30 万个事件片段的数据集。使用这个大型数据集,Q-Transformer 依然有能力学习,甚至能比 RT-1 BC 基准表现更好。

最后,他们把 Q-Transformer 训练的 Q 函数用作可供性模型(affordance model),再与语言规划器组合到一起,类似于 SayCan。
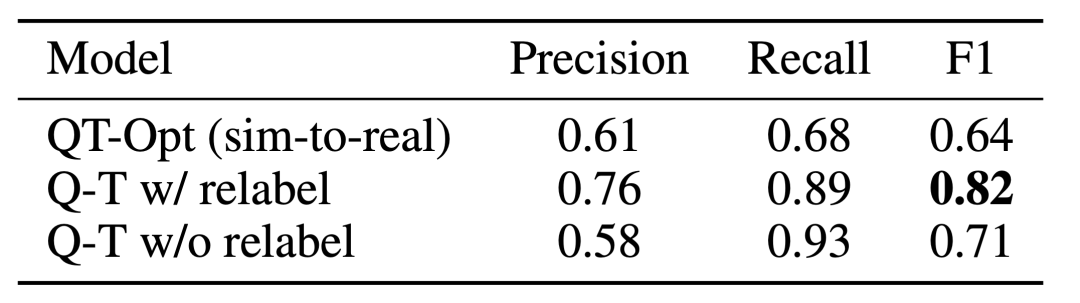
Q-Transformer 可供性估计的效果由于之前的使用 QT-Opt 训练的 Q 函数;如果再将未被采样的任务重新标注为训练期间当前任务的负例,效果还能更好。由于 Q-Transformer 不需要 QT-Opt 训练使用的模拟到真实(sim-to-real)训练,因此如果缺乏合适的模拟,那么使用 Q-Transformer 会更容易。
为了测试完整的「规划 + 执行」系统,他们实验了使用 Q-Transformer 同时进行可供性估计和实际策略执行,结果表明它优于之前的 QT-Opt 和 RT-1 组合。
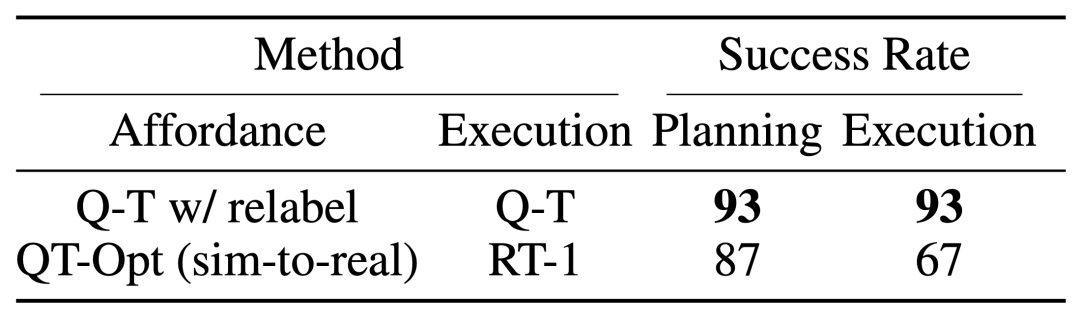
从给定图像的任务可供性值示例中可以看出,针对下游的「规划 + 执行」框架,Q-Transformer 可提供高质量的可供性值。
更多详细内容,请阅读原文。
好了,关于Transformer+强化学习,谷歌DeepMind让大模型成为机器人感知世界的大脑就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “尔森”用心倾听大自然的神秘邀约
- “考生”硕士统考发布报名提醒 考生需及时自查,抓紧时间修改
- “合肥市”“柿柿如意,柿如破竹”…… 高三学子“花式解压”
- “肌肉”磁铁刺激疗法可“对齐”肌肉纤维
- “低价”第15个双11:电商巨头争夺“最低价”、取消预售、开放生态
- “犯罪嫌疑人”湖南新化砍伤一对夫妇的犯罪嫌疑人落网,4人涉嫌窝藏罪被批捕
- “中国移动”中移动市场详情:合作伙伴大会重要发言及发布、反诈、5G应用获奖
- “血液”简单的血液检查调整可使重症监护治疗更安全
- “南充市”落马公安局长收受财物1365万被判7年:悔称利欲熏心,“金钱大厦”瞬间倾覆一生毁灭
- “高粱”河南固始有执法人员带人偷高粱?当地回应:涉事人员为行政执法大队人员,正调查
- “液态”我国学者构建液态金属磁性微型软体机器人,可用于临床医学
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “炮车”评论丨雾炮车昼夜狂喷监测点?斩断伸向环境监测数据作假之“手”
- “人类”有了GPT-4之后,机器人把转笔、盘核桃都学会了
- “产品”用12万UGC造一个爆款 可以科技如何扎根家庭机器人赛道?
- “数据”奇富科技知微实验室揭秘黑市数据交易链条
- “互联网”工业互联网驶入“深水区” 中小企业积极性不足
- “数据”市经济和信息化局发布《北京市首席数据官制度试点工作方案》 全面推行政府首席数据官制度
- “机器人”「天创机器人」完成超亿元C轮融资 ,加速工业智能运维落地应用|早起看早期
- “之家”西部数据 SN770M 2230 SSD 上架:2TB 1559 元









