“摘要”「字少信息量大」,Salesforce、MIT 研究者手把手教 GPT-4「改稿」,数据集已开源
今天,很高兴为大家分享来自机器之心Pro的「字少信息量大」,Salesforce、MIT 研究者手把手教 GPT-4「改稿」,数据集已开源,如果您对「字少信息量大」,Salesforce、MIT 研究者手把手教 GPT-4「改稿」,数据集已开源感兴趣,请往下看。
通过人类评估实验,研究者发现,当 GPT-4 将「稿子」改到第三版的时候,「信息密度」和「语言精炼度」两个因素达到了一种最佳平衡状态。
近年来,自动摘要技术取得了长足的进步,这主要归功于范式的转变 —— 从在标注数据集上进行有监督微调转变为使用大语言模型(LLM)进行零样本 prompt,例如 GPT-4。不需要额外的训练,细致的 prompt 就能实现对摘要长度、主题、风格等方面特征的精细控制。
但一个方面常常被忽视:摘要的信息密度。从理论上讲,作为对另一个文本的压缩,摘要应该比源文件更密集,也就是包含更多的信息。考虑到 LLM 解码的高延迟,用更少的字数涵盖更多的信息非常重要,尤其是对于实时应用而言。
然而,信息量密度是一个开放式的问题:如果摘要包含的细节不足,那么相当于没有信息量;如果包含的信息过多,又不增加总长度,就会变得难以理解。要在固定的 token 预算内传递更多信息,就需要将抽象、压缩、融合三者结合起来。
在最近的一项研究中,来自 Salesforce、MIT 等机构的研究者试图通过征求人类对 GPT-4 生成的一组密度越来越高的摘要的偏好来确定这一限制。对于提升 GPT-4 等大语言模型的「表达能力」,这一方法提供了很多启发。

论文链接:https://arxiv.org/pdf/2309.04269.pdf
数据集地址:https://huggingface.co/datasets/griffin/chain_of_density
具体来说,他们将每个 token 的平均实体数量作为密度的代表,生成了一个初始的、实体稀少的摘要,然后在不增加总长度(总长度为 5 倍)的情况下,反复识别并融合前一个摘要中缺失的 1-3 个实体,每个摘要的实体与 token 比例都高于前一个摘要。根据人类的偏好数据,作者最终确定,人类更喜欢几乎与人类编写的摘要一样密集的摘要,而且比普通 GPT-4 prompt 生成的摘要更密集。
总体来说,该研究的贡献包括:
开发一种基于 prompt 的迭代方法 (CoD),使得摘要的实体密度越来越高;
对 CNN/《每日邮报》文章中越来越密集的摘要进行人工和自动评估,以更好地了解信息量(倾向于更多实体)和清晰度(倾向于更少的实体)之间的权衡;
开源了 GPT-4 摘要、注释和一组 5000 篇未注释的 CoD 摘要,用于评估或提炼。

什么是 CoD
作者制定了一个单一的密度链(CoD)Prompt,即生成一个初始摘要,并使其实体密度不断增加。具体来说,在一个固定的交互次数中,源文本中一组独特的突出实体被识别出来,并在不增加长度的情况下融合到之前的摘要中。
图 2 显示了 Prompt 和输出示例。作者没有规定实体的类型,而是将缺失实体定义为:
相关:与主要故事相关;
具体:描述性的但简洁(5 个字或更少);
新颖:未出现在之前的摘要中;
忠实:存在于文章中;
任何地方:位于文章的任何地方。

作者从 CNN/DailyMail 摘要测试集中随机抽取了 100 篇文章,为其生成 CoD 摘要。为便于参考,他们将 CoD 摘要统计数据与人类撰写的要点式参考摘要以及 GPT-4 在普通 Prompt 下生成的摘要进行比较:「写一篇非常简短的文章摘要。请勿超过 70 个字。」
统计情况
在研究中,作者从直接统计数据和间接统计数据两方面进行了总结。直接统计数据(token、实体、实体密度)由 CoD 直接控制,而间接统计数据则是密集化的预期副产品。
直接统计数据。如表 1 所示,由于从最初冗长的摘要中删除了不必要的词语,第二步平均减少了 5 个 token(从 72 到 67)的长度。实体密度从 0.089 开始,最初低于人类和 Vanilla GPT-4(0.151 和 0.122),经过 5 步密集化后,最终上升到 0.167。

间接统计。抽象度应该会随着每一步 CoD 的进行而增加,因为每增加一个实体,摘要就会被反复改写以腾出空间。作者用提取密度来衡量抽象性:提取片段的平均平方长度 (Grusky et al., 2018)。同样,随着实体被添加到固定长度的摘要中,概念融合度也应随之单调增加。作者用与每个摘要句子对齐的源句子的平均数量来表示融合度。在对齐上,作者使用相对 ROUGE 增益法 (Zhou et al., 2018),,该方法将源句与目标句对齐,直到额外句子的相对 ROUGE 增益不再为正。他们还预计内容分布(Content Distribution),也就是摘要内容所来源的文章中位置,会发生变化。
具体来说,作者预计 CoD 摘要最初会表现出强烈的「引导偏向」(Lead Bias),但随后会逐渐开始从文章的中间和末尾引入实体。为了测量这一点,他们使用了融合中的对齐结果,并测量了所有对齐源句的平均句子等级。
图 3 证实了这些假设:抽象性随着重写步骤的增加而增加(左侧提取密度较低),融合率上升(中图),摘要开始纳入文章中间和末尾的内容(右图)。有趣的是,与人类撰写的摘要和基线摘要相比,所有 CoD 摘要都更具抽象性。

结果
为了更好地理解 CoD 摘要的 tradeoff,作者开展了一项基于偏好的人类研究,并使用 GPT-4 进行了基于评级的评估。
人类偏好。具体来说,对于同样的 100 篇文章(5 个 step *100 = 总共 500 篇摘要),作者向论文的前四位作者随机展示了经过「重新创作」的 CoD 摘要以及文章。根据 Stiennon et al. (2020) 对「好摘要」的定义,每位注释者都给出了自己最喜欢的摘要。表 2 报告了各注释者在 CoD 阶段的第一名得票情况,以及各注释者的汇总情况。总的来说,61% 的第一名摘要(23.0+22.5+15.5)涉及≥3 个致密化步骤。首选 CoD 步数的中位数位于中间(3),预期步数为 3.06。

根据 Step 3 摘要的平均密度,可以大致推断出所有 CoD 候选者的首选实体密度为 ∼ 0.15。从表 1 中可以看出,这一密度与人类编写的摘要(0.151)相一致,但明显高于用普通 GPT-4 Prompt 编写的摘要(0.122)。
自动度量。作为人工评估的补充(如下),作者用 GPT-4 从 5 个维度对 CoD 摘要进行评分(1-5 分):信息量、质量、连贯性、可归属性和整体性。如表 3 所示,密集度与信息量相关,但有一个限度,在步骤 4(4.74)时得分达到顶峰。
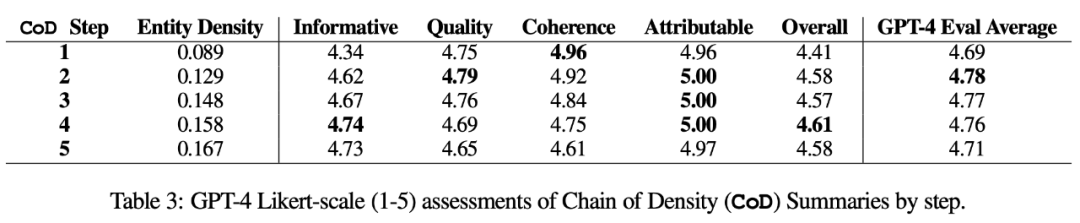
从各维度的平均得分来看,CoD 的第一个和最后一个步骤得分最低,而中间三个步骤得分接近(分别为 4.78、4.77 和 4.76)。
定性分析。摘要的连贯性 / 可读性与信息量之间存在着明显的 trade-off。图 4 中展示了两个 CoD 步骤:一个步骤的摘要因更多细节而得到改善,另一个步骤的摘要则受到损害。平均而言,中间 CoD 摘要最能实现这种平衡,但这种 tradeoff 仍需在今后的工作中去精确定义和量化。

更多论文细节,可参考原论文。

好了,关于「字少信息量大」,Salesforce、MIT 研究者手把手教 GPT-4「改稿」,数据集已开源就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “考生”下半年自考即将开始 省考试院发出温馨提示
- “父亲”父亲的眼神杀
- “这是”自内耗到自洽
- “大桥”G3铜陵长江公铁大桥先导索过江
- “某甲”父亲被羁押继母要离婚,未成年女儿谁来抚养?法官多方努力,难题解决了!
- “亚马逊”哪些以色列芯片公司已被美国企业收购?
- “结构”结核杆菌致病机制获揭示
- “装修”装修公司老板明知公司亏损仍吸引客户签合同,骗取上百人700余万,被判11年
- “射电”穿越80亿光年的快速射电暴源于一场“星系交通事故”
- “必胜客”必胜客最黑暗的料理来了
- “中国移动”中移动市场详情:合作伙伴大会重要发言及发布、反诈、5G应用获奖
- “游戏”中国电信本周市场动态:物联网获奖、推天翼云电脑、云宽带等
- “商家”线上引流 线下承接,本地经济新增量就在巨量本地推
- “中国联通”一周市场详情:天翼物联推连接方案、联通助力亚运会、5G应用获奖
- “中国移动”2023中国移动合作伙伴大会多位高管发言集锦 含杨杰董昕等等
- “细胞”新研究表明一种经过改进的CAR-T细胞有望治疗卵巢癌等实体瘤
- “中国移动”中移动近期市场宣传:保障亚运、推智慧家庭升级计划、开售苹果15
- “月球”目前月球上以中国元素命名的地名共35个
- “中国联通”联通本周宣传重点曝光:匠心网络行浙江站收官、推低频共建共享等
- “摘要”中移动一周市场详情:亮相智博会、开学季营销、反诈、数字员工等









