“开源”开源大模型有望迎接“安卓时刻”,创业公司如何抓住机遇? | 榕汇实战分享
今天,很高兴为大家分享来自高榕资本的开源大模型有望迎接“安卓时刻”,创业公司如何抓住机遇? | 榕汇实战分享,如果您对开源大模型有望迎接“安卓时刻”,创业公司如何抓住机遇? | 榕汇实战分享感兴趣,请往下看。
来源:高榕资本
在科技届,开源早已不只是一种全新的技术趋势和软件开发范式,更是无数开发者和聪明大脑坚定不移的信仰。开源充分展现出一种利他精神带来的整个生态的指数级增长和巨大繁荣。
在大模型时代,开源从一开始就成为题中应有之义。在闭源大模型“北极星”般的指引下,开源大模型亦如雨后春笋,生机无限。尤其是LLaMA2等重磅开源模型的发布和商用、Hugging Face等开源社区的兴起,开源世界被认为有潜力与闭源并驾齐驱。
回望历史,从计算机视觉到今天的大语言模型,开源在AI发展之路上起到了怎样的创新驱动作用?开源社区、开源体系建设者、开发者如何看待这片创新土壤,期待孕育怎样的果实?中小型或者垂直领域创业公司如何拥抱开源AI力量,高效开发自己的模型及应用、建立企业增长护城河?
近期,榕汇邀请深耕开源Infra、开源社区、开源模型与算法等领域的专家,在线研讨开源AI的趋势与未来。


Meta高级副总裁Bill Jia从全局性和长周期的角度,分享过去10年AI生态系统各个层级的演进与开源的驱动力量。
在AI模型层,计算机视觉、语言翻译领域之所以发展到今天如此成熟,开源在其中起到了至关重要的作用。以计算机视觉为例,“CNN(卷积神经网络)一问世就是开源的,后续的一系列模型也基本开源,加速了多轮创新和技术迭代。”
至于今天如火如荼的大语言模型,开源大模型正不断形成生态圈,与此同时也驱动着闭源大模型朝下一代不断升级,Bill Jia预测,大语言模型有机会出现能理解段落与段落之间关联的新模型架构,这会是一个重要的节点。另外,大模型现在对context inputs主要还是考虑spatial relationships, 以后的模型需要考虑inputs temporal时间关联性,这对video generation和logic generation至关重要。这些都是现在大模型的弱点,需要研究创新。开源大模型也为生态系统中的开发者提供更多机遇,包括“未来6到9个月,手机端去运行一些规模相对较小的LLM完全有机会变成现实”。
除了模型层,Bill Jia也系统分析了数据层、AI训练软件平台层、AI框架层及AI硬件层的开源格局。其中在数据层,他期待未来有更多高质量、多元、可信赖的数据集开源,“这对未来进一步提升大语言模型的能力至关重要,其中也存在诸多商业化机会。”

Hugging Face作为AI开源社区界的“顶流”,目前社区已有超过26万个开源模型以及4.6万个开源数据库,并抱有这样一种信念——“未来每家公司都将拥有自己的模型、自己的机器学习能力”。
Hugging Face亚太区首席机器学习工程师尹一峰,基于对社区的一手观察分享了对开源生态趋势的展望。
“我们对开源生态有四点观察:一是百花齐放,强大的开源模型(如LLaMA2)在开源社区发布后,就像寒武纪生命大爆发一样,也被我们称作‘The LLaMA Moment’;二是马太效应,根据我们的观察,排名前1%的模型拥有99%的下载量;三是光速迭代,例如LLaMA和LLaMA2的间隔时间非常短;四是数据为王,随着开源模型越来越强大,愈发凸显优质数据集和数据科学团队的价值,数据决定了训练出来的模型是否具备真正的商业价值。”
关于开源商业模式的讨论由来已久,Hugging Face自身就选择了“开源带动商业”的路径,目前已推出系列付费服务。尹一峰以BloombergGPT、Stability AI、Grammarly等为例,指出结合具体的商业场景及丰富的训练语料,开源项目同样具备商业化潜力。
谈及开源和闭源世界相互之间的良性促进,尹一峰用“开源是闭源的地板,闭源是开源的路灯”来形容。OpenAI等闭源巨头拥有资源和团队优势,从0到1跑通之后为开源社区点亮路灯;随着开源模型一步步增强,众多开发者很快可以基于基础模型做调优并应用到各类场景中,也在倒逼闭源模型进一步迭代。他也认为,“尽管今天大模型领域闭源领先,但未来开源力量终会有潜力与闭源并驾齐驱,如同安卓和苹果生态。”

OpenMMLab开源算法体系是计算机视觉领域全球最有影响力的开源项目之一。上海人工智能实验室青年科学家陈恺介绍了从零建设OpenMMLab的初心、迭代旅程,以及不断向外辐射、打造有价值开源体系的思考。
早在2018年,受统一的深度学习算法框架启发,OpenMMlab应运而生,致力打造计算机视觉领域统一的算法框架,“让开发者在算法和应用开发时免于花大量时间去复现不同算法、做各种各样的参数调优。”
此后,OpenMMlab持续发展和迭代,从最早推出目标检测框架,到图形分类、语义分割、视频理解等等,“基本上每年都会推出一系列的开源框架和应用,直至今天,形成了计算机视觉领域非常完整的生态。”除了统一先进的底层架构,OpenMMLab目前已覆盖30+计算机视觉热点方向,400+算法支持及4000+预训练模型和开箱即用工具。
基于开源算法体系的广泛影响力,OpenMMLab致力进一步拓展外延,带动一批生态项目。目前OpenMMLab开源项目star数超过9万,开源生态项目超过500个,并进一步辐射更大范围的AI社区、推动产学研合作。
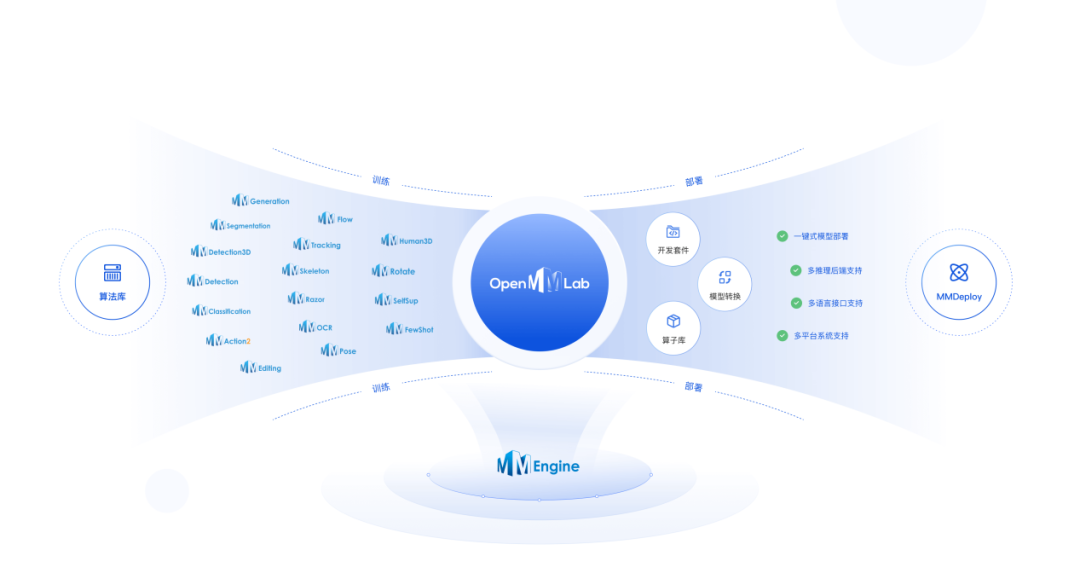
基于强大的开源生态,OpenMMLab也在计算机视觉领域的行业上下游创造价值。上游支持芯片适配,通过算法生态带动国产化软硬件生态链发展;下游则加速计算机视觉技术在企业客户端进行落地,提高行业研发效率。
大语言模型浪潮下,上海人工智能实验室也在近期世界人工智能大会上发布书生·浦语开源模型(InternLM-7B)。除了模型本身,陈恺重点指出,“我们希望通过开源方式,建设一个完整的大模型生态链。”也因此,InternLM-7B围绕数据、预训练、微调、部署、测评等大模型落地关键环节,打造了完整的开源体系,“最终目的是让社区更好地用起来”。

开源生态不断拓宽AI疆域的边界,也为广大创业者和开发者提供了绝佳的创新机遇。那么,创业公司应该如何拥抱这股澎湃的开源力量?研讨对话环节,高榕资本高级副总裁王慧与几位专家探讨了大模型时代企业构建增长护城河的锦囊。
锦囊一:守护Core Business,开疆扩土
面对大模型和开源带来的机会与挑战,Bill Jia给出的建议是“先筑城、再建护城河”。企业首先应当准确理解自身在行业中的生态位置,牢牢守住自己的核心业务(Core Business)和自己的底线(Bottom Line),“看好自己的奶酪”;其次,要对大模型和开源抱有开放态度,并基于新技术去思考是否有可能扩展自身的业务,开疆扩土;最后,大模型带来的变革如同第四次产业革命,终究会一同把蛋糕做大,在这样的过程中要思考可以尽早切入哪些关键版图。
锦囊二:模型选取综合考虑业务场景、合规等因素
开源大模型百花齐放,企业如何选取最适合自己的模型?Hugging Face中国区负责人王铁震指出,仅依赖学术测评是远远不够的,需要企业针对自身业务场景,并用专属数据集进行测试,综合评估模型的能力是否匹配。例如选取文生图模型,美学评分并不是唯一标准,而要综合看是否符合企业的目标受众与场景。这也再次体现出企业建立自身数据集的重要性,“数据集的投资回报是非常长期的,不管未来最火的模型是谁,都可以用它来进行训练和测评。”
此外,王铁震也建议企业在选取开源模型时,需要关注当地合规与监管政策,包括模型的license是否可商用、模型训练时的透明度、训练数据版权问题、数据是否符合价值观等等。
企业的竞争最终靠人才,王铁震也特别建议创业公司可以利用开源社区来发现优秀人才,建立人才竞争力。如有企业开源了垂直领域大模型,可以顺势挖掘社区中的优秀开发者和贡献者,帮助企业更有针对性地锁定和筛选人才。
锦囊三:模型差距无需过忧,唯快不破
针对开源模型在性能表现上对比闭源的差距,陈恺指出,开源模型的迭代速度很快,企业应该将关注重点更多聚焦在自身业务场景和流程上,模型是可以不断去更换和迭代的。“有可能今天你觉得模型效果不好,一个月之后一个新的开源模型出现,之前的问题就解决了;此外我们也发现开源模型的规模也在不断提升,从此前比较普遍的7B,到13B、30B乃至更大量级。”
在这样的竞争格局下,创业企业“唯快不破”。“有些赛道很卷,那么就需要企业以更高效率把一个垂直领域的应用、一个核心场景跑通,进而积累更多用户反馈和来自真实世界的数据,形成数据飞轮,把时间优势转化为企业的护城河。”
锦囊四:沉淀有核心竞争力的数据,长期投入
十方融海创始人黄冠则结合企业一线实践,分享如何基于核心业务落地应用AI大模型。
作为一家数字职业在线教育科技公司,十方融海目前重点关注如何利用AI创新引擎,提升学生的学习体验和教学效率。最初十方融海将大模型技术用于帮助学生在学习短视频制作时,进行文案辅助生成;此后探索用AI来批改语言创作类作业;并进一步思考,是否有可能基于大模型,高效回答学生提出的基础性和知识性问题,提升助教的效率。
“我们快速学习、尝试和迭代,并从今年4月开始,基于LLaMA做微调,研发出OpenBuddy-LLaMA系列开源模型,拥有优秀的问题理解和回答能力。”过程中,黄冠和团队也通过模型优化、数据标注等方式,不断提高回复准确率,也探索模型的多轮对话能力。与此同时,通过在核心业务场景迭代模型,公司也沉淀了有核心竞争力的数据。
今年8月,十方融海发布并开源了OpenBuddy-LLaMA2-70B模型,这是一个基于LLaMA2基座的全新跨语言对话模型,在十方融海内部业务的商用场景测试中已经取得非常好的成绩。
面向未来,黄冠对于中文开源模型及中文语料抱有期待,并且“做好了长期投入的心理准备”,“不要高估大模型短期的效果,也不要低估大模型长期的影响”。
流水不争先,争的是滔滔不绝。开源模型令人目不暇接,但最终给予企业的命题仍旧是——是否足够开放以拥抱技术变化,是否足够有定力守住核心场景。

好了,关于开源大模型有望迎接“安卓时刻”,创业公司如何抓住机遇? | 榕汇实战分享就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “考生”下半年自考即将开始 省考试院发出温馨提示
- “父亲”父亲的眼神杀
- “这是”自内耗到自洽
- “大桥”G3铜陵长江公铁大桥先导索过江
- “某甲”父亲被羁押继母要离婚,未成年女儿谁来抚养?法官多方努力,难题解决了!
- “亚马逊”哪些以色列芯片公司已被美国企业收购?
- “结构”结核杆菌致病机制获揭示
- “装修”装修公司老板明知公司亏损仍吸引客户签合同,骗取上百人700余万,被判11年
- “射电”穿越80亿光年的快速射电暴源于一场“星系交通事故”
- “必胜客”必胜客最黑暗的料理来了
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “炮车”评论丨雾炮车昼夜狂喷监测点?斩断伸向环境监测数据作假之“手”
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等
- “数据”奇富科技知微实验室揭秘黑市数据交易链条
- “融资”国内AI大模型赛道火热,大厂积极跟投布局









