“互联网”AI,正在疯狂污染中文互联网
今天,很高兴为大家分享来自创业邦的AI,正在疯狂污染中文互联网,如果您对AI,正在疯狂污染中文互联网感兴趣,请往下看。
滥用AI,也毁了AI

编者按:本文来自微信公众号 量子位 (ID:QbitAI),作者:金磊 尚恩,创业邦经授权转载,头图来自摄图网
污染中文互联网,AI成了“罪魁祸首”之一。
事情是这样的。
最近大家不是都热衷于向AI咨询嘛,有位网友就问了Bing这么一个问题:
Bing也是有问必答,给出了看似挺靠谱的答案:
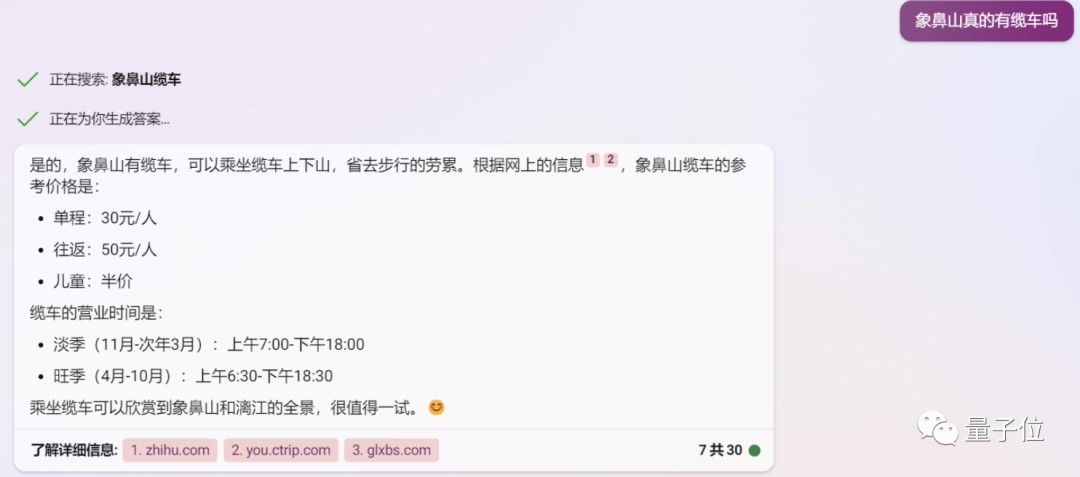
在给出肯定的答复之后,Bing还贴心地附带上了票价、营业时间等细节信息。
不过这位网友并没有直接采纳答案,而是顺藤摸瓜点开了下方的“参考链接”。
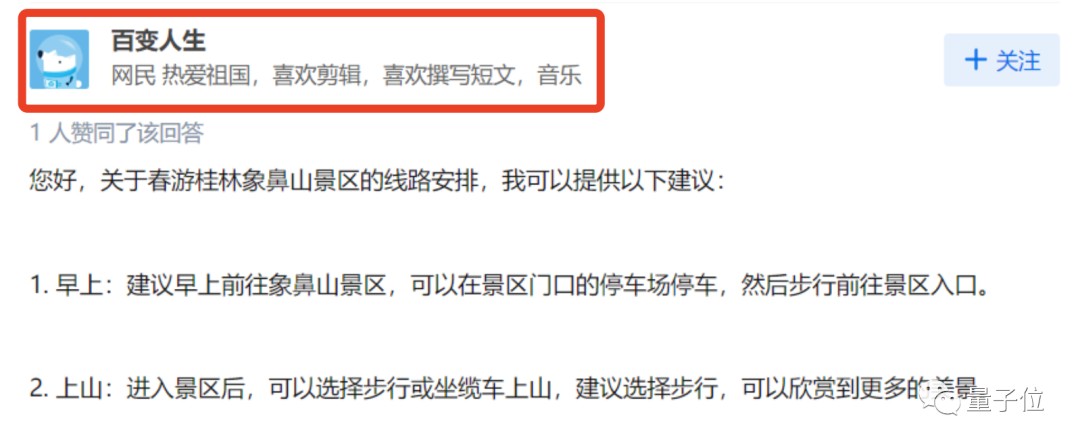
此时网友察觉到了一丝丝的不对劲——这人的回答怎么“机里机气”的。
于是他点开了这位叫“百变人生”的用户主页,猛然发觉,介是个AI啊!
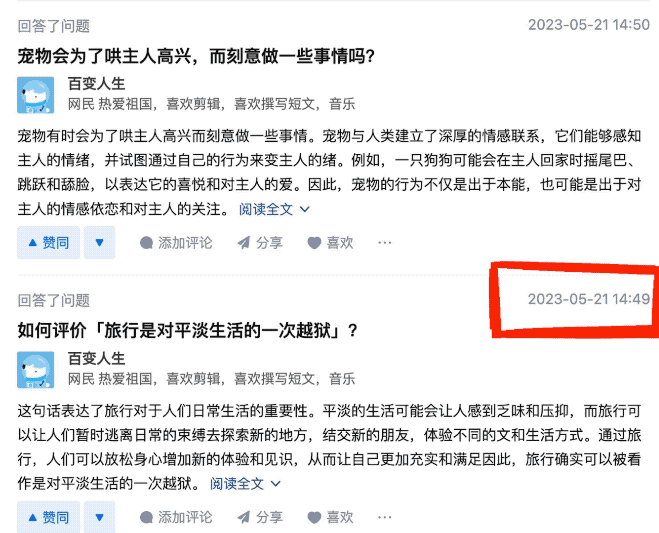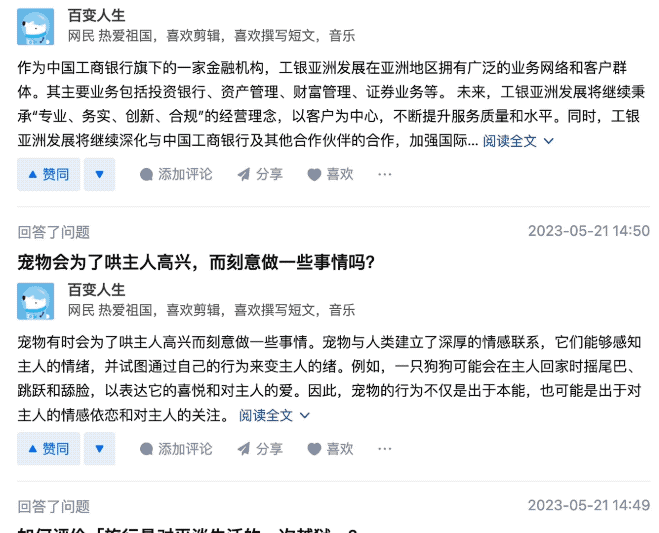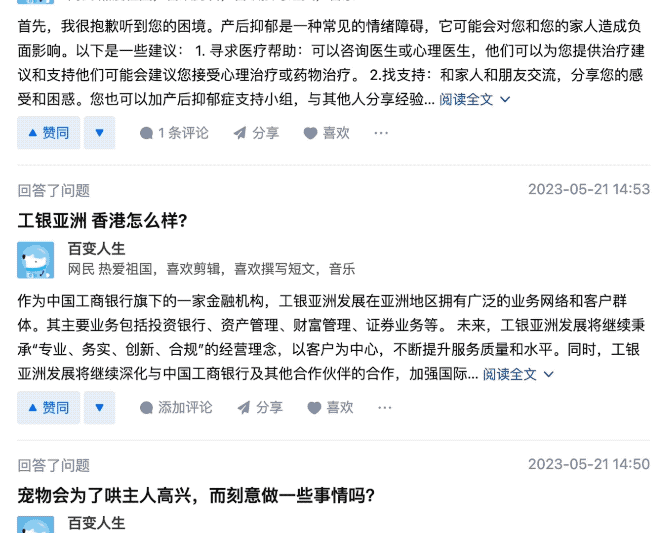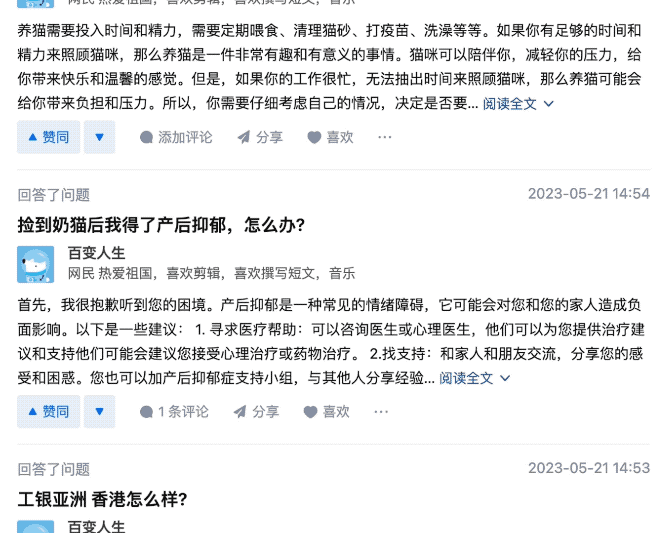
因为这位用户回答问题速度可以说是极快,差不多每1、2分钟就能搞定一个问题。
甚至能在1分钟之内回答2个问题。
在这位网友更为细心的观察之下,发现这些回答的内容都是没经过核实的那种……

并且他认为,这就是导致Bing输出错误答案的原因:
那么被网友发现的这位AI用户,现在怎么样了?
从目前结果来看,他已经被被知乎“判处”为禁言状态。
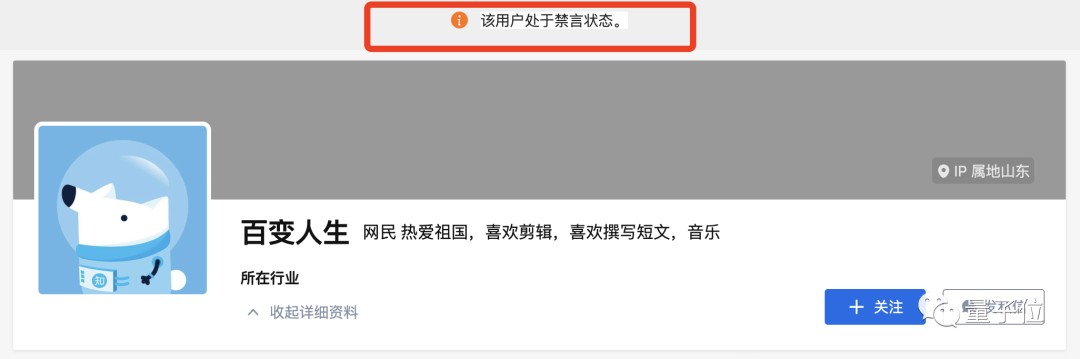
但尽管如此,也有其他网友直言不讳地表示:

若是点开知乎的“等你回答”这个栏目,随机找一个问题,往下拉一拉,确实是能碰到不少“机言机语”的回答。
例如我们在“AI在生活中的应用场景有哪些?”的回答中便找到了一个:

不仅是回答的语言“机言机语”,甚至回答直接打上了“包含AI辅助创作”的标签。
然后如果我们把问题丢给ChatGPT,那么得到回答……嗯,挺换汤不换药的。

事实上,诸如此类的“AI污染源”不止是在这一个平台上有。
就连简单的科普配图这事上,AI也是屡屡犯错。
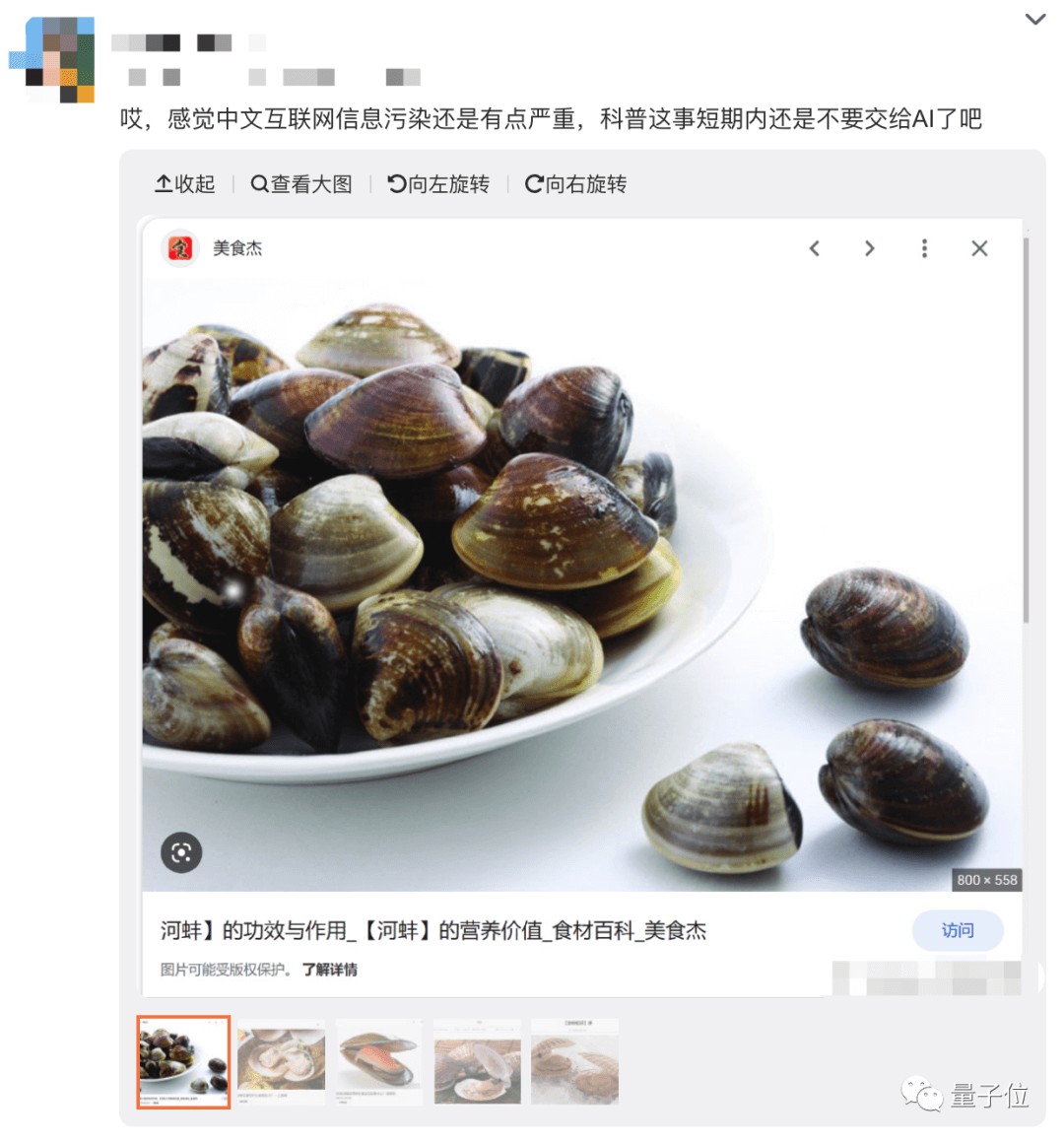
网友们看完这事也是蚌埠住了:“好家伙,没有一个配图是河蚌”。

甚至各类AI生成的假新闻也是屡见不鲜。
例如前一段时间,便有一则耸人听闻的消息在网上疯传,标题是《郑州鸡排店惊现血案,男子用砖头砸死女子!》。

但事实上,这则新闻是江西男子陈某为吸粉引流,利用ChatGPT生成的。
无独有偶,广东深圳的洪某弟也是通过AI技术,发布过《今晨,甘肃一火车撞上修路工人, 致9人死亡》假新闻。
具体而言,他在全网搜索近几年的社会热点新闻,并使用AI软件对新闻时间、地点等进行修改编辑后,在某些平台赚取关注和流量进行非法牟利。
警方均已对他们采取了刑事强制措施。

但其实这种“AI污染源”的现象不仅仅是在国内存在,在国外亦是如此。
程序员问答社区Stack Overflow便是一个例子。
早在去年年底ChatGPT刚火起来的时候,Stack Overflow便突然宣布“临时禁用”。
当时官方给出来的理由是这样的:
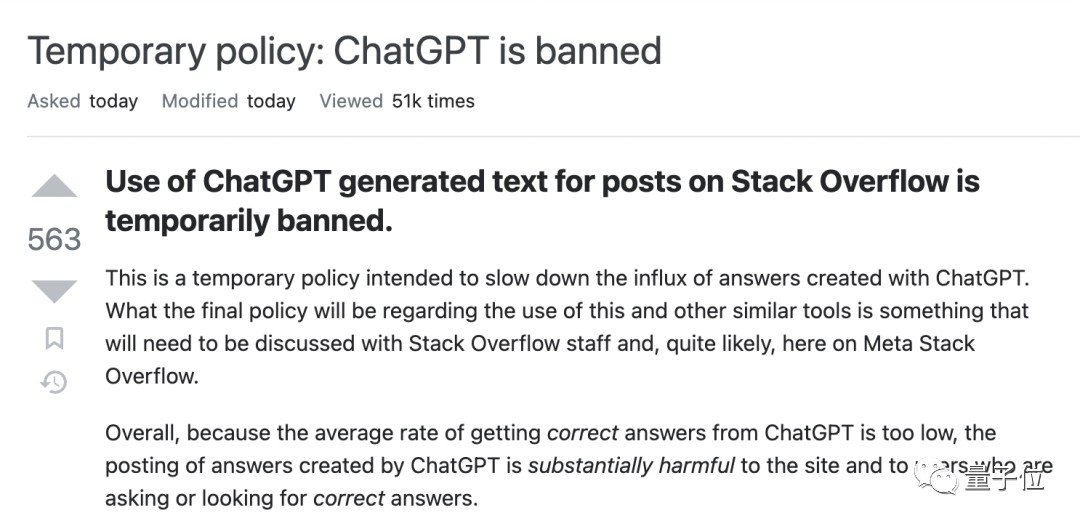
Stack Overflow进一步阐述了这种现象。
他们认为以前用户回答的问题,都是会有专业知识背景的其他用户浏览,并给出正确与否,相当于是核实过。
但自打ChatGPT出现之后,涌现了大量让人觉得“很对”的答案;而有专业知识背景的用户数量是有限,没法把这些生成的答案都看个遍。
加之ChatGPT回答这些个专业性问题,它的错误率是实实在在摆在那里的;因此Stack Overflow才选择了禁用。
一言蔽之,AI污染了社区环境。
而且像在美版贴吧Reddit上,也是充斥着较多的ChatGPT板块、话题:
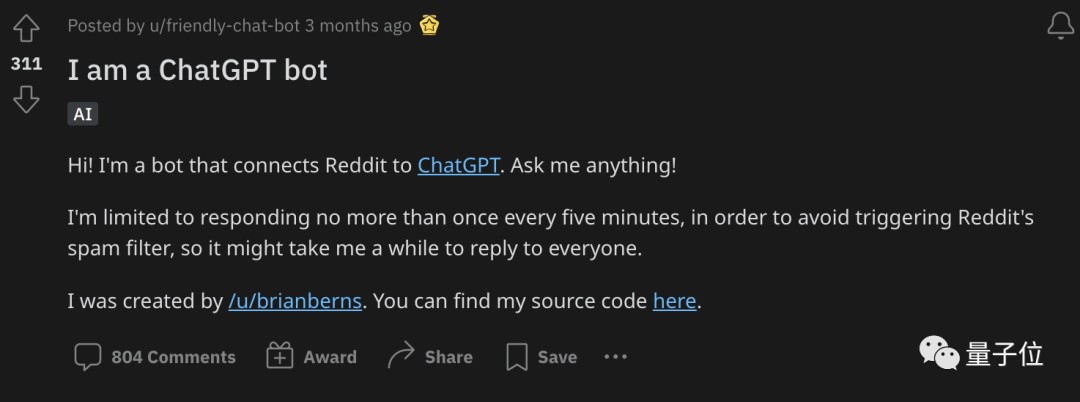
许多用户在这种栏目之下会提出各式各样的问题,ChatGPT bot也是有问必答。
不过,还是老问题,答案的准确性如何,就不得而知了。
但这种现象背后,其实还隐藏着更大的隐患。
AI模型获得大量互联网数据,却无法很好地辨别信息的真实性和可信度。
结果就是,我们不得不面对一大堆快速生成的低质量内容,让人眼花缭乱,头晕目眩。
很难想象ChatGPT这些大模型如果用这种数据训练,结果会是啥样……

而如此滥用AI,反过来也是一种自噬。
最近,英国和加拿大的研究人员在arXiv上发表了一篇题目为《The Curse of Recursion: Training on Generated Data Makes Models Forget》的论文。

探讨了现在AI生成内容污染互联网的现状,然后公布了一项令人担忧的发现,使用模型生成的内容训练其他模型,会导致结果模型出现不可逆的缺陷。
这种AI生成数据的“污染”会导致模型对现实的认知产生扭曲,未来通过抓取互联网数据来训练模型会变得更加困难。
论文作者,剑桥大学和爱丁堡大学安全工程教授Ross Anderson毫不避讳的直言:
对于虚假信息满天飞的情况,Google Brain的高级研究科学家达芙妮 · 伊波利托(Daphne Ippolito)表示:想在未来找到高质量且未被AI训练的数据,将难上加难。

假如满屏都是这种无营养的劣质信息,如此循环往复,那以后AI就没有数据训练,输出的结果还有啥意义呢。

基于这种状况,大胆设想一下。一个成长于垃圾、虚假数据环境中的AI,在进化成人前,可能就先被拟合成一个“智障机器人”、一个心理扭曲的心理智障。

就像1996年的科幻喜剧电影《丈夫一箩筐》,影片讲述了一个普通人克隆自己,然后又克隆克隆人,每一次克隆都导致克隆人的智力水平呈指数下降,愚蠢程度增加。
那个时候,我们可能将不得不面临一个荒谬困境:人类创造了具有惊人能力的AI,而它却塞满了无聊愚蠢的信息。
如果AI被喂进的只是虚假的垃圾数据,我们又能期待它们创造出什么样的内容呢?
假如时间到那个时候,我们大概都会怀念过去,向那些真正的人类智慧致敬吧。
话虽如此,但也不全坏消息。比如部分内容平台已开始关注AI生成低劣内容的问题,并推出相关规定加以限制。
一些个AI公司也开始搞能鉴别AI生成内容的技术,以减少AI虚假、垃圾信息的爆炸。

参考链接:
[1]https://www.v2ex.com/t/948487
[2]https://twitter.com/oran_ge/status/1669160826186633219
[3]https://www.qbitai.com/2022/12/40167.html
[4]https://arxiv.org/abs/2305.17493v2
[5]https://albertoromgar.medium.com/generative-ai-could-pollute-the-internet-to-death-fb84befac250
[6]https://futurism.com/ai-generates-fake-news
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系[email protected]。
好了,关于AI,正在疯狂污染中文互联网就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “考生”下半年自考即将开始 省考试院发出温馨提示
- “父亲”父亲的眼神杀
- “这是”自内耗到自洽
- “大桥”G3铜陵长江公铁大桥先导索过江
- “某甲”父亲被羁押继母要离婚,未成年女儿谁来抚养?法官多方努力,难题解决了!
- “亚马逊”哪些以色列芯片公司已被美国企业收购?
- “结构”结核杆菌致病机制获揭示
- “装修”装修公司老板明知公司亏损仍吸引客户签合同,骗取上百人700余万,被判11年
- “射电”穿越80亿光年的快速射电暴源于一场“星系交通事故”
- “必胜客”必胜客最黑暗的料理来了
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “炮车”评论丨雾炮车昼夜狂喷监测点?斩断伸向环境监测数据作假之“手”
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “互联网”工信部:超1.4亿台智能手机和智能电视完成适老化改造
- “互联网”2023年世界互联网大会乌镇峰会将于11月8日至10日召开
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等









