“视频”生成视频如此简单,给句提示就行,还能在线试玩
今天,很高兴为大家分享来自机器之心Pro的生成视频如此简单,给句提示就行,还能在线试玩,如果您对生成视频如此简单,给句提示就行,还能在线试玩感兴趣,请往下看。
动动嘴皮子就能生成视频的新研究来了。
你输入文字,让 AI 来生成视频,这种想法在以前只出现在人们的想象中,现在,随着技术的发展,这种功能已经实现了。
近年来,生成式人工智能在计算机视觉领域引起巨大的关注。随着扩散模型的出现,从文本 Prompt 生成高质量图像,即文本到图像的合成,已经变得非常流行和成功。
最近的研究试图通过在视频领域复用文本到图像扩散模型,将其成功扩展到文本到视频生成和编辑的任务。虽然这样的方法取得了可喜的成果,但大部分方法需要使用大量标记数据进行大量训练,这可能对许多用户来讲太过昂贵。
为了使视频生成更加廉价,Jay Zhangjie Wu 等人去年提出的 Tune-A-Video 引入了一种机制,可以将 Stable Diffusion (SD) 模型应用到视频领域。只需要调整一个视频,从而让训练工作量大大减少。虽然这比以前的方法效率提升很多,但仍需要进行优化。此外,Tune-A-Video 的生成能力仅限于 text-guided 的视频编辑应用,而从头开始合成视频仍然超出了它的能力范围。
本文中,来自 Picsart AI Resarch (PAIR) 、得克萨斯大学奥斯汀分校等机构的研究者在 zero-shot 以及无需训练的情况下,在文本到视频合成的新问题方向上向前迈进了一步,即无需任何优化或微调的情况下根据文本提示生成视频。

论文地址:https://arxiv.org/pdf/2303.13439.pdf
项目地址:https://github.com/Picsart-AI-Research/Text2Video-Zero
试用地址:https://huggingface.co/spaces/PAIR/Text2Video-Zero
下面我们看看效果如何。例如一只熊猫在冲浪;一只熊在时代广场上跳舞:

该研究还能根据目标生成动作:

此外,还能进行边缘检测:

本文提出的方法的一个关键概念是修改预训练的文本到图像模型(例如 Stable Diffusion),通过时间一致的生成来丰富它。通过建立在已经训练好的文本到图像模型的基础上,本文的方法利用它们出色的图像生成质量,增强了它们在视频领域的适用性,而无需进行额外的训练。
为了加强时间一致性,本文提出两个创新修改:(1)首先用运动信息丰富生成帧的潜在编码,以保持全局场景和背景时间一致;(2) 然后使用跨帧注意力机制来保留整个序列中前景对象的上下文、外观和身份。实验表明,这些简单的修改可以生成高质量和时间一致的视频(如图 1 所示)。
 尽管其他人的工作是在大规模视频数据上进行训练,但本文的方法实现了相似甚至有时更好的性能(如图 8、9 所示)。
尽管其他人的工作是在大规模视频数据上进行训练,但本文的方法实现了相似甚至有时更好的性能(如图 8、9 所示)。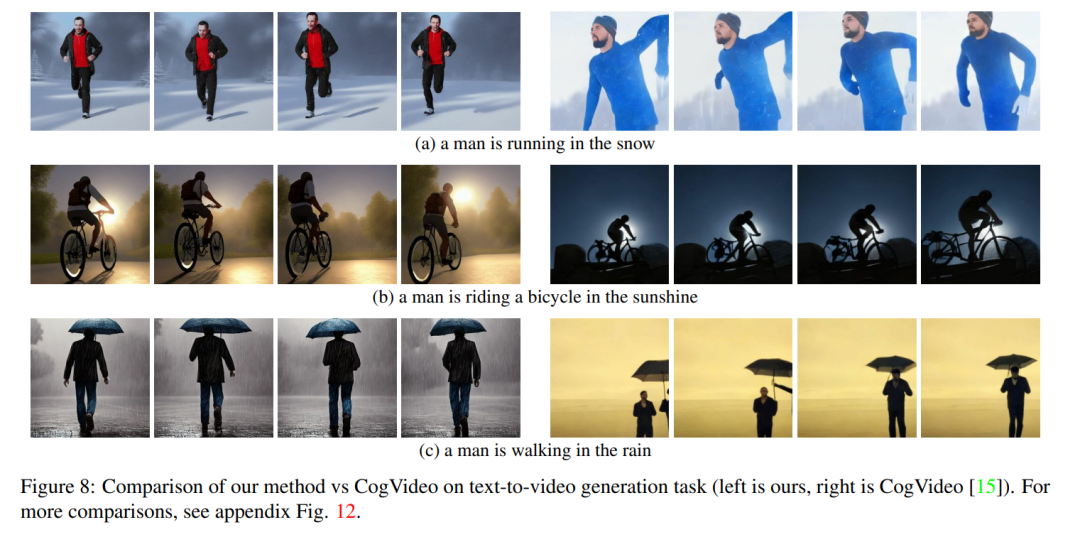

本文的方法不仅限于文本到视频的合成,还适用于有条件的(见图 6、5)和专门的视频生成(见图 7),以及 instruction-guided 的视频编辑,可以称其为由 Instruct-Pix2Pix 驱动的 Video Instruct-Pix2Pix(见图 9)。



方法简介
在这篇论文中,本文利用 Stable Diffusion (SD)的文本到图像合成能力来处理 zero-shot 情况下文本到视频的任务。由于需要生成视频而不是图像,SD 应该在潜在代码序列上进行操作。朴素的方法是从标准高斯分布独立采样 m 个潜在代码,即 N (0, I) ,并应用 DDIM 采样以获得相应的张量
N (0, I) ,并应用 DDIM 采样以获得相应的张量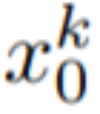 ,其中 k = 1,…,m,然后解码以获得生成的视频序列
,其中 k = 1,…,m,然后解码以获得生成的视频序列
 。然而,如图 10 的第一行所示,这会导致完全随机的图像生成,仅共享
。然而,如图 10 的第一行所示,这会导致完全随机的图像生成,仅共享 所描述的语义,而不具有物体外观或运动的一致性。
所描述的语义,而不具有物体外观或运动的一致性。

为了解决这个问题,本文建议采用以下两种方法:(i)在潜在编码 之间引入运动动态,以保持全局场景的时间一致性;(ii)使用跨帧注意力机制来保留前景对象的外观和身份。下面详细描述了本文使用的方法的每个组成部分,该方法的概述可以在图 2 中找到。
之间引入运动动态,以保持全局场景的时间一致性;(ii)使用跨帧注意力机制来保留前景对象的外观和身份。下面详细描述了本文使用的方法的每个组成部分,该方法的概述可以在图 2 中找到。

注意,为了简化符号,本文将整个潜在代码序列表示为: 。
。
实验
定性结果
Text2Video-Zero 的所有应用都表明它成功生成了视频,其中全局场景和背景具有时间一致性,前景对象的上下文、外观和身份在整个序列中得到了保持。
在文本转视频的情况下,可以观察到它生成与文本提示良好对齐的高质量视频(见图 3)。例如,绘制的熊猫可以自然地在街上行走。同样,使用额外的边缘或姿势指导 (见图 5、图 6 和图 7),生成了与 Prompt 和指导相匹配的高质量视频,显示出良好的时间一致性和身份保持。
 在 Video Instruct-Pix2Pix(见图 1)的情况下,生成的视频相对于输入视频具有高保真,同时严格遵循指令。
在 Video Instruct-Pix2Pix(见图 1)的情况下,生成的视频相对于输入视频具有高保真,同时严格遵循指令。与 Baseline 比较
本文将其方法与两个公开可用的 baseline 进行比较:CogVideo 和 Tune-A-Video。由于 CogVideo 是一种文本到视频的方法,本文在纯文本引导的视频合成场景中与它进行了比较;使用 Video Instruct-Pix2Pix 与 Tune-A-Video 进行比较。
为了进行定量对比,本文使用 CLIP 分数对模型评估,CLIP 分数表示视频文本对齐程度。通过随机获取 CogVideo 生成的 25 个视频,并根据本文的方法使用相同的提示合成相应的视频。本文的方法和 CogVideo 的 CLIP 分数分别为 31.19 和 29.63。因此,本文的方法略优于 CogVideo,尽管后者有 94 亿个参数并且需要对视频进行大规模训练。
图 8 展示了本文提出的方法的几个结果,并提供了与 CogVideo 的定性比较。这两种方法在整个序列中都显示出良好的时间一致性,保留了对象的身份以及背景。本文的方法显示出更好的文本 - 视频对齐能力。例如,本文的方法在图 8 (b) 中正确生成了一个人在阳光下骑自行车的视频,而 CogVideo 将背景设置为月光。同样在图 8 (a) 中,本文的方法正确地显示了一个人在雪地里奔跑,而 CogVideo 生成的视频中雪地和奔跑的人是看不清楚的。
Video Instruct-Pix2Pix 的定性结果以及与 per-frame Instruct-Pix2Pix 和 Tune-AVideo 在视觉上的比较如图 9 所示。虽然 Instruct-Pix2Pix 每帧显示出良好的编辑性能,但它缺乏时间一致性。这在描绘滑雪者的视频中尤其明显,视频中的雪和天空使用不同的样式和颜色绘制。使用 Video Instruct-Pix2Pix 方法解决了这些问题,从而在整个序列中实现了时间上一致的视频编辑。
虽然 Tune-A-Video 创建了时间一致的视频生成,但与本文的方法相比,它与指令指导的一致性较差,难以创建本地编辑,并丢失了输入序列的细节。当看到图 9 左侧中描绘的舞者视频的编辑时,这一点变得显而易见。与 Tune-A-Video 相比,本文的方法将整件衣服画得更亮,同时更好地保留了背景,例如舞者身后的墙几乎保持不变。Tune-A-Video 绘制了一堵经过严重变形的墙。此外,本文的方法更忠实于输入细节,例如,与 Tune-A-Video 相比,Video Instruction-Pix2Pix 使用所提供的姿势绘制舞者(图 9 左),并显示输入视频中出现的所有滑雪人员(如图 9 右侧的最后一帧所示)。Tune-A-Video 的所有上述弱点也可以在图 23、24 中观察到。


好了,关于生成视频如此简单,给句提示就行,还能在线试玩就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “考生”下半年自考即将开始 省考试院发出温馨提示
- “父亲”父亲的眼神杀
- “这是”自内耗到自洽
- “大桥”G3铜陵长江公铁大桥先导索过江
- “某甲”父亲被羁押继母要离婚,未成年女儿谁来抚养?法官多方努力,难题解决了!
- “亚马逊”哪些以色列芯片公司已被美国企业收购?
- “结构”结核杆菌致病机制获揭示
- “装修”装修公司老板明知公司亏损仍吸引客户签合同,骗取上百人700余万,被判11年
- “射电”穿越80亿光年的快速射电暴源于一场“星系交通事故”
- “必胜客”必胜客最黑暗的料理来了
- “视频”一个山东男人在中年离开编制后
- “猪獾”男子发视频“捕获猪獾让狗撕咬”,警方:构成非法狩猎罪,已移送起诉
- “汽车”威马破产,车评人被骂惨?
- “数字”音视频互联网如何借助AIGC跃迁?七牛云为客户做了这些服务
- “视频”评论丨你不会是于文亮,也不必是于文亮
- “灵长类”报告:超51种灵长类动物在视频平台遭不当对待
- “李子”李子柒或将复出?文化类短视频如何“轻舟已过万重山”
- “枇杷”保花堂枇杷秋梨膏3瓶到手19.9元:可干吃可冲饮
- “中国移动”中国移动陈怀达:5G专网收入连年翻番 移动云全网累计投产80万台
- “芯片”中国移动研究院联合知存科技完成基于NOR-Flash存算一体芯片的视频超分技术验证









