“模型”千元预算半天训练,效果媲美主流大模型,开源可商用中文LLaMA-2
今天,很高兴为大家分享来自机器之心Pro的千元预算半天训练,效果媲美主流大模型,开源可商用中文LLaMA-2,如果您对千元预算半天训练,效果媲美主流大模型,开源可商用中文LLaMA-2感兴趣,请往下看。
LLaMA-2 相较于 LLaMA-1,引入了更多且高质量的语料,实现了显著的性能提升,全面允许商用,进一步激发了开源社区的繁荣,拓展了大型模型的应用想象空间。然而,从头预训练大模型的成本相当高,被戏称 「5000 万美元才能入局」,这使得许多企业和开发者望而却步。那么,如何以更低的成本构建自己的大型模型呢?
作为大模型降本增效的领导者,Colossal-AI 团队充分利用 LLaMA-2 的基础能力,采用高效的训练方法,仅使用约 8.5B token 数据、15 小时、数千元的训练成本,成功构建了性能卓越的中文 LLaMA-2,在多个评测榜单性能优越。
相较于原始 LLaMA-2,在成功提升中文能力的基础上,进一步提升其英文能力,性能可与开源社区同规模预训练 SOTA 模型媲美。秉承 Colossal-AI 团队一贯的开源原则,完全开源全套训练流程、代码及权重,无商用限制,并提供了一个完整的评估体系框架 ColossalEval,以实现低成本的可复现性。相关方案还可迁移应用到任意垂类领域和从头预训练大模型的低成本构建。
开源代码与权重:https://github.com/hpcaitech/ColossalAI

性能表现

注:基于 ColossalEval 评分,括号中分数来源于对应模型官方发布的榜单分数,C-Eval 分数来源于官网 Leaderboard。
在常见的中、英文评测榜单,可以看到,在英文 MMLU 榜单中,Colossal-LLaMA-2-7B-base 在低成本增量预训练的加持下,克服了灾难性遗忘的问题,能力逐步提升(44.47 -> 53.06),在所有 7B 规模的模型中,表现优异。
在中文榜单中,主要对比了 CMMLU, AGIEVAL, GAOKAO 与 C-Eval,效果远超基于 LLaMA-2 的其他中文汉化模型。即使与其他采用中文语料,可能花费上千万元成本,从头预训练的各大知名模型相比,Colossal-LLaMA-2 在同规模下仍表现抢眼。尤其是与原始 LLaMA-2 相比,在中文能力上有了质的飞跃 (CMMLU: 32.97 -> 49.89)。
而通过 SFT、LoRA 等方式微调,能有效注入基座模型的知识与能力十分有限,不能较好的满足高质量领域知识或垂类模型应用的构建的需求。
为了更好的评估模型的性能,Colossal-AI 团队不仅仅依赖于量化的指标,还对于模型的不同方面进行了人工的评估,以下是一些例子:


从整个训练的 Loss 记录来看,在利用 Colossal-AI 系统降本增效能力的同时,模型收敛性也得到充分保证,仅通过约 8.5 B tokens(85 亿 tokens),数千元算力成本,让模型达到如此惊艳的效果。而市面上的大模型动辄使用几万亿 token 进行训练才有效果保证,成本高昂。

那么 Colossal-AI 团队是如何把训练成本降低,并达到如此的效果的呢?
词表扩充与模型初始化
LLaMA-2 原始词表并未针对中文做特定优化,所包含的中文词有限,导致在中文语料上理解力不足。因此,首先对 LLaMA-2 进行了词表的扩充。
Colossal-AI 团队发现:
词表的扩充不仅可以有效提升字符串序列编码的效率,并且使得编码序列包含更多的有效信息,进而在篇章级别编码和理解上,有更大的帮助。
然而,由于增量预训练数据量较少,扩充较多的单词反而会导致某些单词或组合无实际意义,在增量预训练数据集上难以充分学习,影响最终效果。
过大的词表会导致 embedding 相关参数增加,从而影响训练效率。
因此,经过反复实验,同时考虑了训练的质量与训练的效率,Colossal-AI 团队最终确定将词表从 LLaMA-2 原有的 32000 扩充至 69104。
有了扩充好的词表,下一步就是基于原有的 LLaMA-2 初始化新词表的 embedding。为了更好的迁移 LLaMA-2 原有的能力,实现从原有 LLaMA-2 到 中文 LLaMA-2 能力的快速迁移,Colossal-AI 团队利用原有的 LLaMA-2 的权重,对新的 embedding 进行均值初始化。既保证了新初始化的模型在初始状态下,英文能力不受影响,又可以尽可能的无缝迁移英文能力到中文上。
数据构建
为了更大程度的降低训练的成本,高质量的数据在其中起着关键作用,尤其是对于增量预训练,对于数据的质量,分布都有着极高的要求。为了更好的筛选高质量的数据,Colossal-AI 团队构建了完整的数据清洗体系与工具包,以便筛选更为高质量的数据用于增量预训练。
以下图片展示了 Colossal-AI 团队数据治理的完整流程:

除了常见的对数据进行启发式的筛选和去重,还对重点数据进行了打分和分类筛选。合适的数据对于激发 LLaMA-2 的中文能力,同时克服英文的灾难性遗忘问题,有着至关重要的作用。
最后,为了提高训练的效率,对于相同主题的数据,Colossal-AI 团队对数据的长度进行了排序,并根据 4096 的最大长度进行拼接。
训练策略
多阶段训练
在训练方面,针对增量预训练的特点,Colossal-AI 团队设计了多阶段,层次化的增量预训练方案,将训练的流程划分为三个阶段:

大规模预训练阶段:目标是通过大量语料训练,使得模型可以产出相对较为流畅的文本。该阶段由 LLaMA-2 完成,经过此阶段,模型已经掌握大量英文知识,并可以根据 Next Token Prediction 输出流畅的结果。
中文知识注入阶段:该阶段依赖于高质量的中文知识,一方面增强了模型对于中文知识的掌握程度,另一方面提升了模型对于新增中文词表中单词的理解。
相关知识回放阶段:该阶段致力于增强模型对于知识的理解与泛化能力,缓解灾难性遗忘问题。
多阶段相辅相成,最终保证模型在中英文的能力上齐头并进。
分桶训练
增量预训练对于数据的分布极为敏感,均衡性就尤为重要。因此,为了保证数据的均衡分布,Colossal-AI 团队设计了数据分桶的策略,将同一类型的数据划分为 10 个不同的 bins。在训练的过程中,每个数据桶中均匀的包含每种类型数据的一个 bin,从而确保了每种数据可以均匀的被模型所利用。
评估体系
为了更好的评估模型的性能,Colossal-AI 团队搭建了完整的评估体系 - ColossalEval,希望通过多维度对大语言模型进行评估。流程框架代码完全开源,不仅支持结果复现,也支持用户根据自己不同的应用场景自定义数据集与评估方式。评估框架特点总结如下:
涵盖针对于大语言模型知识储备能力评估的常见数据集如 MMLU,CMMLU 等。针对于单选题这样的形式,除了常见的比较 ABCD 概率高低的计算方式,增加更为全面的计算方式,如绝对匹配,单选困惑度等,以求更加全面的衡量模型对于知识的掌握程度。
支持针对多选题的评估和长文本评估。
支持针对于不同应用场景的评估方式,如多轮对话,角色扮演,信息抽取,内容生成等。用户可根据自己的需求,有选择性的评估模型不同方面的能力,并支持自定义 prompt 与评估方式的扩展。
构建通用大模型到垂类大模型迁移的桥梁
由 Colossal-AI 团队的经验来看,基于 LLaMA-2 构建中文版模型,可基本分为以下流程:
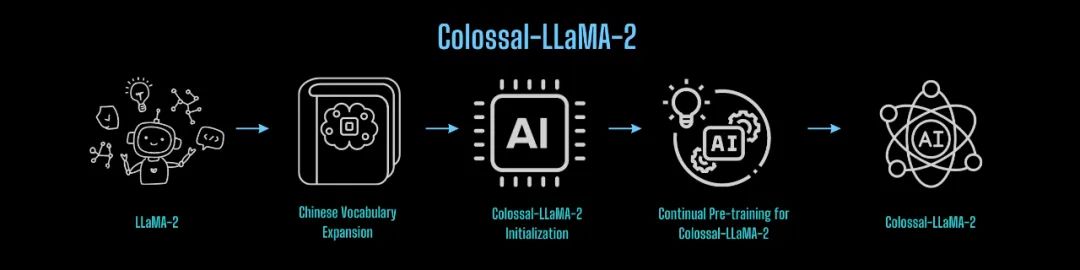
那么这套方案是否可以复用呢?
答案是肯定的,并且在业务落地的场景中是非常有意义的。
随着 ChatGPT 掀起的人工智能浪潮,全球各大互联网巨头、AI 公司、创企、高校和研究机构等,纷纷在通用大模型的赛道上策马狂奔。然而,通用大模型通用能力的背后往往是针对特定领域内知识的不足,因此,在实际落地上,大模型幻觉的问题就变的尤为严重。针对业务微调固然可以有一定的收获,但垂类大模型的缺失导致应用落地存在性能瓶颈。如果可以快速低成本构造一个垂类大模型,再基于垂类大模型进行业务微调,一定能在业务落地上更进一步,占得先机与优势。
将以上流程应用在任意领域进行知识迁移,即可低成本构建任意领域垂类基座大模型的轻量化流程:

对于从头预训练构建基础大模型,也可借鉴上述经验与 Colossal-AI 降本增效能力,以最低成本高效完成。
系统优化
上述 Colossal-LLaMA-2 的亮眼表现和成本优势,构建在低成本 AI 大模型开发系统 Colossal-AI 之上。
Colossal-AI 基于 PyTorch,可通过高效多维并行、异构内存等,降低 AI 大模型训练 / 微调 / 推理的开发与应用成本,提升模型任务表现,降低 GPU 需求等。仅一年多时间便已在 GitHub 开源社区收获 GitHub Star 3 万多颗,在大模型开发工具与社区细分赛道排名世界第一,已与世界 500 强在内的多家知名厂商联合开发 / 优化千亿 / 百亿参数预训练大模型或打造垂类模型。
Colossal-AI 云平台
为了进一步提高 AI 大模型开发和部署效率,Colossal-AI 已进一步升级为 Colossal-AI 云平台,以低代码 / 无代码的方式供用户在云端低成本进行大模型训练、微调和部署,快速将各种模型接入到个性化的应用中。

目前 Colossal-AI 云平台上已经预置了 Stable diffusion, LLaMA-2 等主流模型及解决方案,用户只需上传自己的数据即可进行微调,同时也可以把自己微调之后的模型部署成为 API,以实惠的价格使用 A10, A800, H800 等 GPU 资源,无需自己维护算力集群以及各类基础设施。更多应用场景、不同领域、不同版本的模型、企业私有化平台部署等正不断迭代。
ColossalAI 云平台现已开启公测,注册即可获得代金券,欢迎参与并提出反馈。
Colossal-AI 云平台:platform.luchentech.com
Colossal-AI 云平台文档:https://docs.platform.colossalai.com/
Colossal-AI 开源地址:https://github.com/hpcaitech/ColossalAI
好了,关于千元预算半天训练,效果媲美主流大模型,开源可商用中文LLaMA-2就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “小行星”我国2030年前后 实现载人登月
- “都是”A股的觉醒之年!
- “孩子”一生的功课
- “益康”倍益康上市几个月收入净利都大减 市值仅几亿 创始人张文有啥办法?
- “科幻”嘉宾共话科幻的未来:被视为“珍贵市场”,中国科幻正青春
- “灯会”红星观察|自贡灯会走出“春节舒适区”:首次试水中秋国庆主题灯会火出圈背后
- “华为”新麒麟全面替代!曝华为正在清理骁龙机型库存:掀起全线新品的“洪流”
- “鸟类”评论丨大楼玻璃贴膜防鸟撞,城市的天空如何助鸟自由飞翔?
- “同济大学”四川“无臂青年”彭超参与杭州亚残运会火炬传递,曾用脚写字考上同济大学研究生
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “炮车”评论丨雾炮车昼夜狂喷监测点?斩断伸向环境监测数据作假之“手”
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等
- “数据”奇富科技知微实验室揭秘黑市数据交易链条
- “融资”国内AI大模型赛道火热,大厂积极跟投布局









