“缓存”6.7k Star量的vLLM出论文了,让每个人都能轻松快速低成本地部署LLM服务
今天,很高兴为大家分享来自机器之心Pro的6.7k Star量的vLLM出论文了,让每个人都能轻松快速低成本地部署LLM服务,如果您对6.7k Star量的vLLM出论文了,让每个人都能轻松快速低成本地部署LLM服务感兴趣,请往下看。
机器之心专栏
编辑:Panda
利用操作系统的虚拟内存管理方法来提升LLM推理吞吐量。
今年六月,来自加州大学伯克利分校等机构的一个研究团队开源了 vLLM(目前已有 6700 多个 star),其使用了一种新设计的注意力算法 PagedAttention,可让服务提供商轻松、快速且低成本地发布 LLM 服务。

在当时的博客文章中,该团队宣称 vLLM 能实现比 HuggingFace Transformers 高 24 倍的吞吐量!
八月底,该项目还与其它另外 7 个开源项目一道获得了 a16z 开源人工智能资助计划的首轮资助。
现在离 vLLM 最初宣布时差不多已过去三个月,他们终于发布了这篇关于 vLLM 和 PagedAttention 的研究论文,其中详细解释了他们如何通过类似操作系统虚拟内存管理的机制来实现高效的 LLM 服务。该论文已被将于十月底在德国举办的 ACM 操作系统原理研讨会(SOSP 2023)接收。

论文:https://arxiv.org/abs/2309.06180
代码:https://github.com/vllm-project/vllm
文档:https://vllm.readthedocs.io/
GPT 和 PaLM 等大型语言模型(LLM)的出现催生出了开始对我们的工作和日常生活产生重大影响的新应用,比如编程助理和通用型聊天机器人。
许多云计算公司正竞相以托管服务的方式提供这些应用。但是,运行这些应用的成本非常高,需要大量硬件加速器,如 GPU。根据最近的估计,相比于传统的关键词查询方法,处理一个 LLM 请求的成本超过其 10 倍以上。考虑到成本如此之高,提高 LLM 服务系统的吞吐量(并由此降低单位请求的成本)就变得更为重要了。
LLM 的核心是自回归 Transformer 模型。该模型可基于输入(prompt)和其之前输出的 token 序列生成词(token),一次生成一个。对于每次请求,这个成本高昂的过程都会重复,直到模型输出终止 token。这种按序列的生成过程会让工作负载受到内存限制,从而无法充分利用 GPU 的计算能力,并会限制服务的吞吐量。
通过批量方式同时处理多个请求可以提高吞吐量。但是,要在单一批次中处理许多请求,就需要高效地管理每个请求所占用的内存空间。
举个例子,图 1(左)展示了一个 130 亿参数的 LLM 在一台 40GB RAM 的英伟达 A100 GPU 上的内存分布。

其 65% 的内存都分配给了模型权重,而模型权重在提供服务期间是不会变化的。
30% 的内存是用于存储请求的动态状态。对 Transformer 而言,这些状态由与注意力机制关联的键(key)和值(value)张量构成,通常被称为 KV 缓存,其表示用于生成序列中新输出 token 的之前 token 上下文。
其余占比很小的内存则是用于其它数据,包括激活 —— 评估 LLM 时创建的临时张量。
由于模型权重恒定不变,激活也只会占用少量 GPU 内存,因此对 KV 缓存的管理方式就成了决定最大批量大小的关键。如果管理方式很低效,KV 缓存内存就会极大限制批量大小,并由此限制 LLM 的吞吐量,如图 1(右)所示。
来自 UC 伯克利等机构的这个研究团队在论文中表示,他们观察到当前的 LLM 服务系统都没有高效地管理 KV 缓存内存。主要原因是它们会将请求的 KV 缓存保存在邻接的内存空间中,因为大多数深度学习框架都需要将张量存储在相邻连续的内存中。
但是,不同于传统深度学习工作负载中的张量,KV 缓存有其自己的独特性质:它会在模型生成新 token 的过程中随时间动态地增长和缩小,而且它的持续时间和长度是无法事先知晓的。

这些特性使得现有系统的方法极其低效,这主要体现在两方面:
第一,现有系统存在内部和外部内存碎片的问题。
为了将请求的 KV 缓存存储在相邻连续的空间中,现有系统会预先分配一块限制了请求最大长度的相邻连续内存。这会导致严重的内部碎片化,因为请求的实际长度可能比其最大长度短很多。
此外,就算能事先知道实际长度,预先分配内存的方法依然很低效。因为那一整块内存在请求的生命周期中都被占用了,其它更短的请求无法使用这一块内存 —— 尽管可能其中很大一部分都未被使用。
此外,外部内存碎片可能也很显著,因为每个请求预先分配的内存大小可能都不同。
事实上,我们可以在图 2 的分析中看到,在现有系统中,仅有 20.4%-38.2% 的 KV 缓存内存会用于存储实际的 token 状态。

第二,现有系统无法利用内存共享的机会。
LLM 服务通常会使用先进的解码算法,例如并行采样和波束搜索,这些方法可为每个请求生成多个输出。在这些场景中,由多个序列组成的请求可以部分共享它们的 KV 缓存。但是,现有系统不可能使用内存共享,因为不同序列的 KV 缓存存储在分开的相邻连续空间中。
为了解决上述限制,该团队提出了一种注意力算法 PagedAttention;该算法的灵感来自操作系统(OS)解决内存碎片化和内存共享的方案:使用分页机制的虚拟内存。
PagedAttention 会将请求的 KV 缓存分成一块块的,每一块(block)都包含一定数量 token 的注意力键和值。在 PagedAttention 中,KV 缓存的块不一定要存储在相邻连续空间中。
这样一来,就能以一种更为灵活的方式来管理 KV 缓存,就像是操作系统的虚拟内存:你可以将那些块看作是分页,将 token 看作是字节,将请求视为进程。通过使用相对较小的块并按需分配它们,这种设计可以减少内部碎片。
此外,它还能消除外部碎片,因为所有块的大小都相同。
最后,它还能实现以块为粒度的内存共享;这种内存共享支持与同一请求相关的不同序列,甚至也支持不同的请求。
立足于 PagedAttention,该团队构建了一个高吞吐量的分布式 LLM 服务引擎 vLLM,其几乎做到了 KV 缓存内存的零浪费。
vLLM 使用了块级的内存管理和抢占式的请求调度 —— 这些机制都是配合 PagedAttention 一起设计的。vLLM 支持 GPT、OPT 和 LLaMA 等各种大小的常用 LLM,包括那些超出单个 GPU 内存容量的 LLM。
研究者基于多种模型和工作负载进行了实验评估,结果表明:相比于当前最佳的系统,vLLM 能在完全不影响准确度的前提下将 LLM 服务吞吐量提升 2-4 倍。而且当序列更长、模型更大、解码算法更复杂时,vLLM 带来的提升还会更加显著。
总体而言,该研究的贡献如下:
确认了提供 LLM 服务时的内存分配挑战并量化了它们对服务性能的影响。
提出了 PagedAttention,这是一种对存储在非相邻连续的分页内存中的 KV 缓存进行操作的注意力算法,其灵感来自操作系统中的虚拟内存和分页。
设计并实现了 vLLM,这是一个基于 PagedAttention 构建的分布式 LLM 服务引擎。
通过多种场景对 vLLM 进行了实验评估,结果表明其表现显著优于 FasterTransformer 和 Orca 等之前最佳方案。
方法概况
vLLM 的架构如图 4 所示。

vLLM 采用一种集中式调度器(scheduler)来协调分布式 GPU 工作器(worker)的执行。KV 缓存管理器由 PagedAttention 驱动,能以分页方式有效管理 KV 缓存。具体来说,KV 缓存管理器通过集中式调度器发送的指令来管理 GPU 工作器上的物理 KV 缓存内存。
PagedAttention
不同于传统的注意力算法,PagedAttention 支持将连续的键和值存储在非相邻连续的内存空间中。
具体来说,PagedAttention 会将每个序列的 KV 缓存分成 KV 块。每一块都包含固定数量 token 的键和值的向量;这个固定数量记为 KV 块大小(B)。令第 j 个 KV 块的键块为 K_j,值块为 V_j。则注意力计算可以转换为以下形式的对块的计算:

其中 A_{i,j} 是在第 j 个 KV 块上的注意力分数的行向量。
在注意力计算期间,PagedAttention 核会分开识别并获取不同的 KV 块。
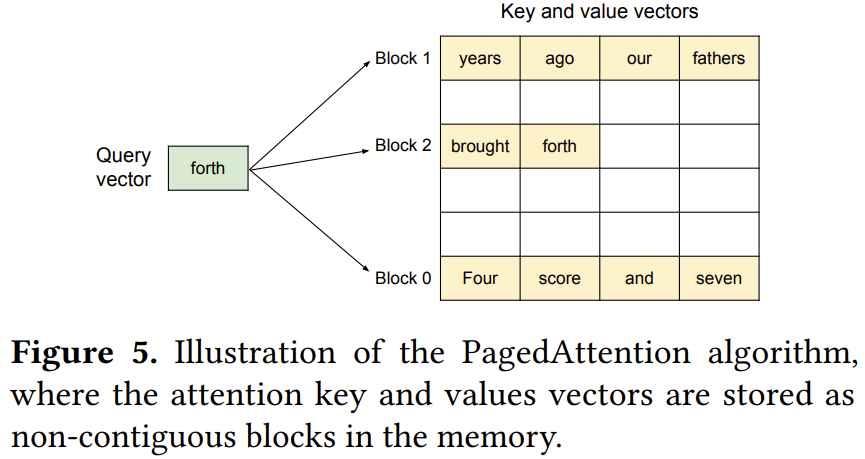 图 5 给出了 PagedAttention 的一个示例:其键和值向量分布在三个块上,并且这三个块在物理内存上并不相邻连续。
图 5 给出了 PagedAttention 的一个示例:其键和值向量分布在三个块上,并且这三个块在物理内存上并不相邻连续。每一次,这个 PagedAttention 核都会将查询 token(forth)的查询向量 q_i 与一个块(比如 0 块中的 Four score and seven 的键向量)中键向量 K_j 相乘,以计算注意力分数 A_{i,j};然后再将 A_{i,j} 与块中的值向量 V_j 相乘,得到最终的注意力输出 o_i。
综上所述,PagedAttention 算法能让 KV 块存储在非相邻连续的物理内存中,从而让 vLLM 实现更为灵活的分页内存管理。
KV 缓存管理器
使用 PagedAttention,该团队将 KV 缓存组织为固定大小的 KV 块,就像虚拟内存中的分页。
对 KV 缓存的请求会被表示成一系列逻辑 KV 块,在生成新 token 和它们的 KV 缓存时从左向右填充。最后一个 KV 块中未填充的位置留给未来填充。
使用 PagedAttention 和 vLLM 进行解码
图 6 通过一个示例展示了 vLLM 在对单个输入序列的解码过程中执行 PagedAttention 和管理内存的方式。

从全局来看,在每次解码迭代中,vLLM 首先会选取一组候选序列来批处理,并为新请求的逻辑块分配物理块。
然后,vLLM 会将当前迭代的所有输入 token 连接起来,组成一个序列并将其输入到 LLM。在 LLM 的计算过程中,vLLM 使用 PagedAttention 核来访问以逻辑 KV 块形式存储的之前的 KV 缓存,然后将新生成的 KV 缓存保存到物理 KV 块中。
在一个 KV 块中存储多个 token(块大小 > 1)可让 PagedAttention 核并行处理多个位置的 KV 缓存,由此可以提升硬件使用率并降低延迟。
图 7 给出了 vLLM 管理两个序列的内存的示例。

应用于其它解码场景
在许多成功的 LLM 应用中,LLM 服务必须要能提供更为复杂的解码场景 —— 有复杂的访问模式和更多的内存共享机会。研究者展示了 vLLM 的一般适用性。他们在论文中讨论过的场景包括并行采样、波束搜索、共享前缀、混合解码方法。
比如图 8 展示了一个带有两个输出的并行编码的例子。

由于两个输出共享同一个 prompt,所以在 prompt 阶段只需为 prompt 的状态在内存空间中保留一个副本;这两个序列的 prompt 的逻辑块都会映射到同一个物理块。更多分析和示例请参阅原论文。
调度和抢占
LLM 面临着一个独特挑战:输入 LLM 的 prompt 的长度变化范围很大,并且输出结果的长度也无法事先知晓,而要依输入 prompt 和模型的情况而定。随着请求和相应输出数量的增长,vLLM 可能会为了存储新生成的 KV 缓存而耗尽 GPU 的物理块。
对于这种情况,vLLM 需要回答两个经典问题:(1) 应该淘汰(evict)哪些块?(2) 如果再次需要,如何恢复已淘汰的块?
通常来说,淘汰策略是使用启发式方法来预测将在最远的未来访问的块然后淘汰那个块。由于这里已知是一起访问一个序列的所有块,所以该团队实现了一种全清或不动的淘汰策略,即要么淘汰序列的所有块,要么就全不淘汰。此外,一个请求中的多个序列会被组成一个序列组来一起调度。一个序列组中的序列总是会被一起抢占或重新调度,因为这些序列之间存在潜在的内存共享。
为了解答第二个有关如何恢复已淘汰块的问题,研究者考虑了两种技术:
交换。这是大多数虚拟内存实现使用的经典技术,即把已淘汰的分页复制到磁盘上的一个交换空间。在这里,研究者的做法是把已淘汰块复制到 CPU 内存。如图 4 所示,除了 GPU 块分配器之外,vLLM 还包括一个 CPU 块分配器,用以管理交换到 CPU RAM 的物理块。
重新计算。这个做法很简单,就是当被抢占的序列被重新调度时,直接重新计算 KV 缓存。请注意,重新计算的延迟可能比原始延迟低得多。
交换和重新计算的性能取决于 CPU RAM 和 GPU 内存之间的带宽以及 GPU 的计算能力。
分布式执行
vLLM 能有效用于分布式的硬件设置,因为其支持 Transformers 上广泛使用的 Megatron-LM 式张量模型并行化策略。该策略遵循 SPMD(单程序多数据)执行调度方案,其中线性层会被分开以执行逐块的矩阵乘法,并且 GPU 会通过 allreduce 操作不断同步中间结果。
具体来说,注意力算子会被分散在注意力头维度上,每个 SPMD 过程负责多头注意力中一个注意力头子集。
实现
vLLM 是一个端到端服务提供系统,具有 FastAPI 前端和基于 GPU 的推理引擎。
该前端扩展了 OpenAI API 接口,允许用户为每个请求自定义采样参数,例如最大序列长度和波束宽度。
vLLM 引擎由 8500 行 Python 代码和 2000 行 C++/CUDA 代码写成。
该团队也用 Python 开发了一些与控制相关的组件,包括调度器和块管理器,还为 PagedAttention 等关键操作开发了定制版 CUDA 核。
至于模型执行器,他们使用 PyTorch 和 Transformer 实现了常用的 LLM,比如 GPT、OPT 和 LLaMA。
他们为分布式 GPU 工作器之间的张量通信使用了 NCCL。
评估
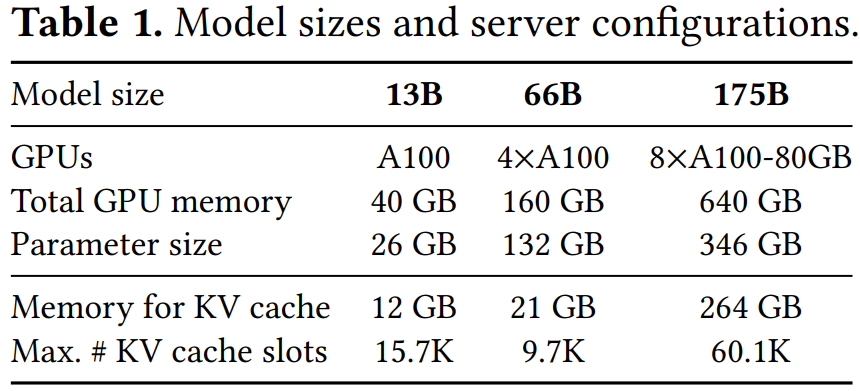
为了验证 vLLM 的效果,该团队进行了一系列实验评估。表 1 给出了模型大小和服务器配置情况。
基础采样
在 ShareGPT 数据集上,vLLM 可以维持比 Orca (Oracle) 高 1.7-2.7 倍的请求率,比 Orca (Max) 则高 2.7-8 倍,同时还能维持相近的延迟,如图 12 上面一行和图 13a 所示。


在 Alpaca 数据集上的结果也类似。
并行采样和波束搜索
如图 14 上面一行所示,如果要采样的序列数量很多,则 vLLM 能在 Orca 基准的基础上带来更大的提升。

图中下面一行则展示了不同波束宽度的波束搜索结果。由于波束搜索支持更多共享,所以 vLLM 带来的性能优势还要更大。
图 15 展示了内存节省量,计算方法是用因为共享而节省的块数除以不使用共享时的总块数。

共享前缀
如图 16a 所示,当共享单样本前缀时,vLLM 的吞吐量比 Orca (Oracle) 高 1.67 倍。此外,当共享更多样本时(图 16b),vLLM 能实现比 Orca (Oracle) 高 3.58 倍的吞吐量。

聊天机器人
从图 17 可以看出,相比于三个 Orca 基准模型,vLLM 可以维持高 2 倍的请求率。

该团队也进行了消融实验,表明 PagedAttention 确实有助于 vLLM 提升效率。他们也研究了块大小与重新计算和交换技术的影响。详情参阅原论文。
好了,关于6.7k Star量的vLLM出论文了,让每个人都能轻松快速低成本地部署LLM服务就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “在我”忆来只把旧书读
- “科博会”芜湖科博会集中展示大国重器
- “诗人”带着大海散步的人
- “宁德”宁德时代三季报:业绩增速放缓、海外市场份额扩大
- “新材料”信金控股完成新一期人民币基金首关
- “同比增长”失守3000点后,A股市场的危与机|智氪
- “商务部”商务部:达成共识!
- “基金”又一家基金公司换董事长,年内公募高管变动人数增至321人
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “教师”北京化工大学回应学院院长被指骚扰教师:已成立工作专班,对师德失范问题零容忍
- “注意力”别再「浪费」GPU了,FlashAttention重磅升级,实现长文本推理速度8倍提升
- “侧翼”将专家知识与深度学习结合,清华团队开发DeepSEED进行高效启动子设计
- “三星”内存市场有望回暖 三星正计划提升DDR5内存产量
- “蛋白质”利用进化扩散进行蛋白生成,微软开源新型蛋白质生成AI框架EvoDiff
- “算法”Transformer的上下文学习能力是哪来的?
- “紫光”vivo Y17s手机现身跑分库 搭载4GB内存
- “模型”Andrej Karpathy:大模型有内存限制,这个妙招挺好用
- “染色体”Y染色体完整测序被揭开,有望破解遗传、疾病诸多秘密
- “至尊版”24GB+1TB大内存版Redmi k60至尊版今日开售 支持144Hz刷新率
- “职级”快手宣布升级职级体系,职级序列双轨变单轨 职级总数微调为10个









