“人声”配乐行业危,谷歌出手解决音乐伴奏问题,人均音乐人不远了
今天,很高兴为大家分享来自机器之心Pro的配乐行业危,谷歌出手解决音乐伴奏问题,人均音乐人不远了,如果您对配乐行业危,谷歌出手解决音乐伴奏问题,人均音乐人不远了感兴趣,请往下看。
唱歌配什么音乐?这次 AI 说了算。
谷歌继续向生成音频领域发起挑战!
不同于前几天自家研发的文本生成音乐模型 MusicLM,可以生成各种音乐,这次他们最新发布的 SingSong(两项研究仅隔了四天),是一个可以生成器乐来伴奏输入人声的系统,可为音乐家和非音乐家提供一种新方式来创作以他们自己的声音为特色的音乐。

论文地址:https://arxiv.org/pdf/2301.12662.pdf
论文主页:https://storage.googleapis.com/sing-song/index.html
不得不说,谷歌接连不断的发布新研究,这次着实给配乐界的人不少压力。
下面我们先来听听效果,下面是一段原始声音:
加入配乐后的原始音乐 Ground Truth:
加入 SingSong-XL 的配乐:
加入 SingSong-Base 的配乐:
你可能认为上述配乐时长太短了,不用担心,SingSong 还能生成 30S 的配乐:
从音乐技术角度来看,SingSong 改进了两个关键的领域:源分离和音频生成建模。研究使用 Kim 等人提出的源分离算法,将大量不同的音乐语料库(1M 首曲目)分离为成对的人声和器乐源,构成并行数据。然后,采用 AudioLM —— 一种涉及中间表示层次结构的音频无条件生成模型 —— 适用于在给定人声乐器的条件下生成音频到音频的建模,并以监督的方式在源分离数据上训练它。
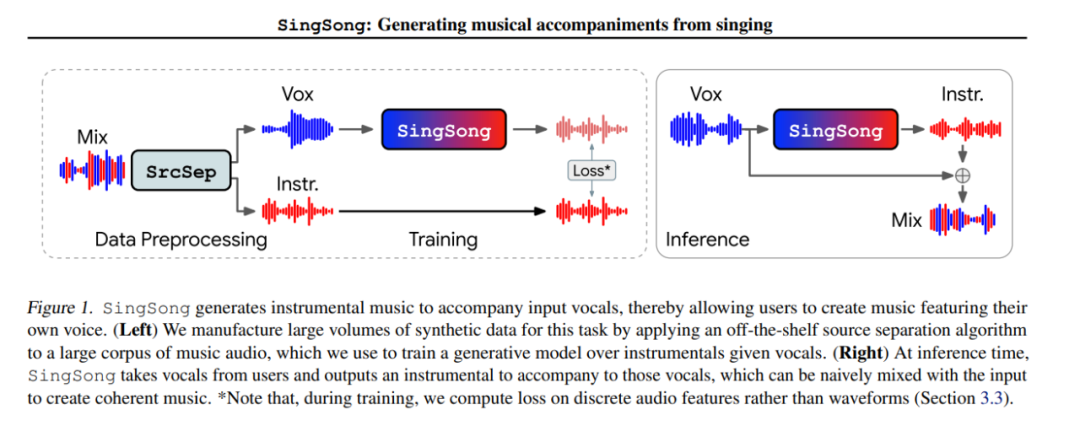
研究的主要挑战在于建立一个系统,从而能将训练期间观察到的源头分离的人声输入,泛化到现实世界中孤立的人声,这也将会符合用户对系统的预期。初步实验结果表明,模型强烈倾向于从源分离的声音中几乎听不见的伪音重建乐器 —— 当输入孤立的声音时,这些模型产生了无意义的输出。为了提高泛化,研究提出了两种输入语音特征化策略:(1)在语音输入中添加噪声以隐藏伪音,(2)仅使用来自 AudioLM 的最粗糙的中间表示作为条件输入。在感知相关的指标上,这些功能加在一起,相对于默认的 AudioLM 功能提高了 55% 的孤立人声性能。
一项比较研究中为听众呈现了两种人声相同的人声 - 器乐混音,与来自强检索基线的听众相比,参与研究的听众喜好更偏向 SingSong 器乐,该基线使用人声的音乐特征(节拍和键)作为查询,从而检索具有相似特征的人类创作的乐器。与此检索基线中的器乐相比,66% 的听众更喜欢 SingSong 器乐。此外,与 ground truth 乐器相比,34% 的听众更喜欢 SingSong 乐器。
方法概览
如下图所示,为了与训练给定人声乐器条件下的的音频到音频生成模型相适配,研究采用了 AudioLM。在训练过程中,研究分别使用声源分离的人声和乐器作为输入和目标,在输入中添加白噪声,以隐藏在源分离人声中存在的乐器残留。此外,研究重新采用了 AudioLM 中的离散特征化方案,从预训练的 w2v-BERT 模型中提取语义代码,与此同时,从预训练的 SoundStream(端到端神经音频编解码器)中提取粗声码。研究针对几个输入特征进行了实验。
研究训练了 T5(一个编码器 - 解码器 Transformer)来预测给定输入代码的目标代码。在推理期间,研究先是使用该模型生成粗声码,然后使用单独训练的模型生成给定粗的细代码,最后使用 SoundStream 解码。
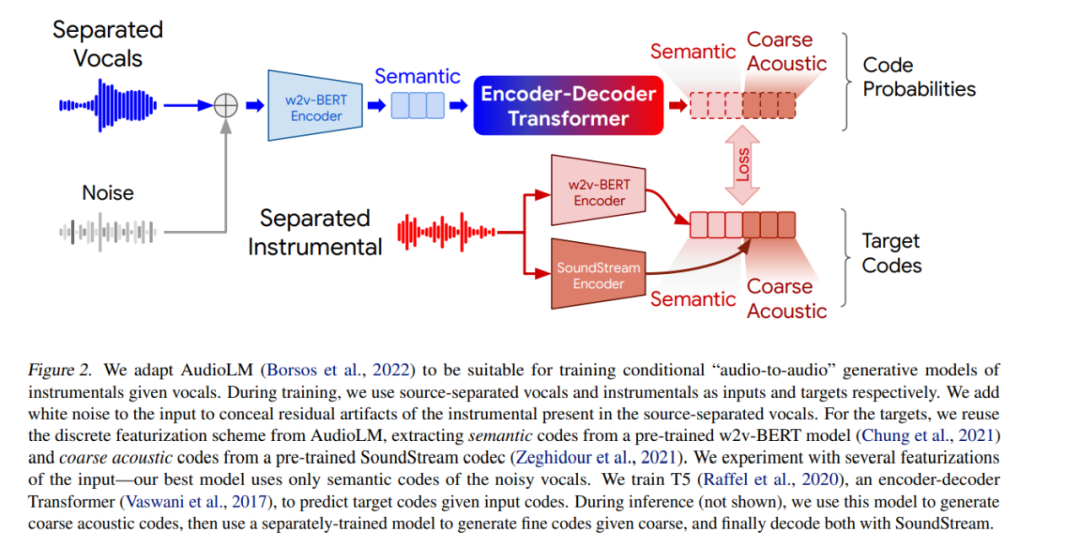
实验结果
研究对输入声音的不同特征进行了实验。研究发现(1)噪声 (noise):在语音输入中添加白噪声以掩盖源分离伪噪声,以及(2)S-SA:从默认 AudioLM 特征 (SA-SA) 中去除人声的声学代码,导致了强泛化。也就是说,在 MUSDB18-dev 上使用隔离和源分离人声进行评估时,使用这种特征进行训练的结果几乎相同。
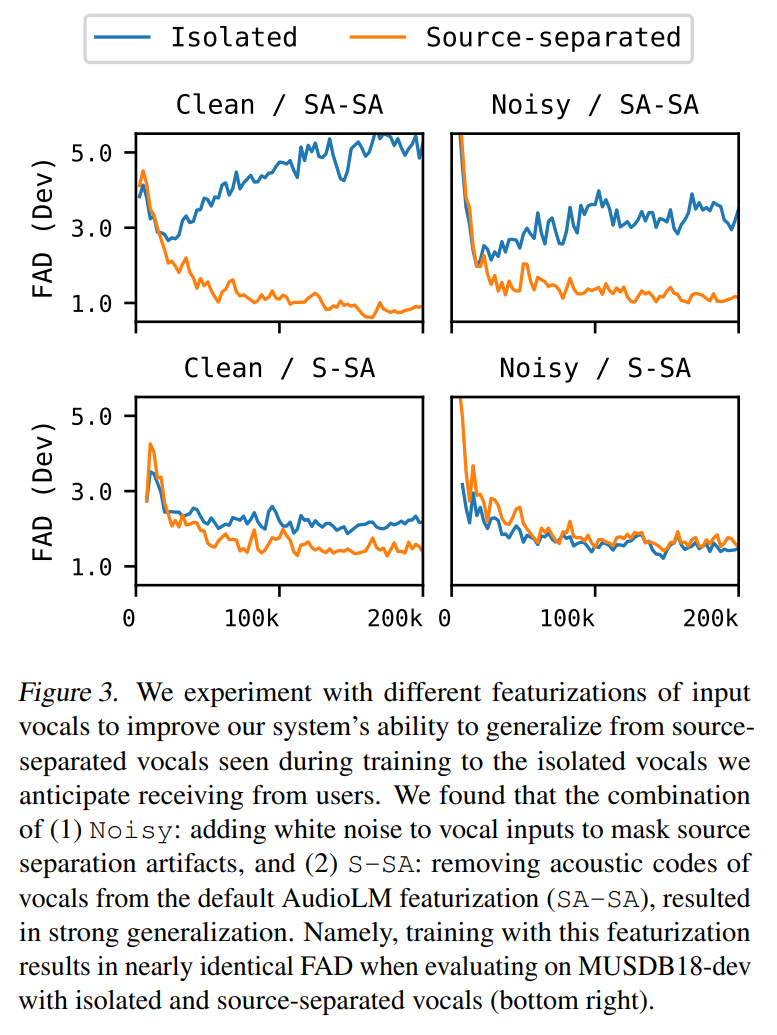
为了更好地理解每个特性的效果,研究还对输入和目标进行了额外的特性实验。研究从输入(A-SA)、目标(SA-A)以及输入和目标(A-A)中删除语义码 —— 声音码在合成中不可或缺,所以不能从目标中删除。研究只在噪声条件下进行这些额外的实验,因为在没有噪声的条件下训练的两个模型性能都很差,而且实验的计算成本很高。表 1 展示了所有模型结果。
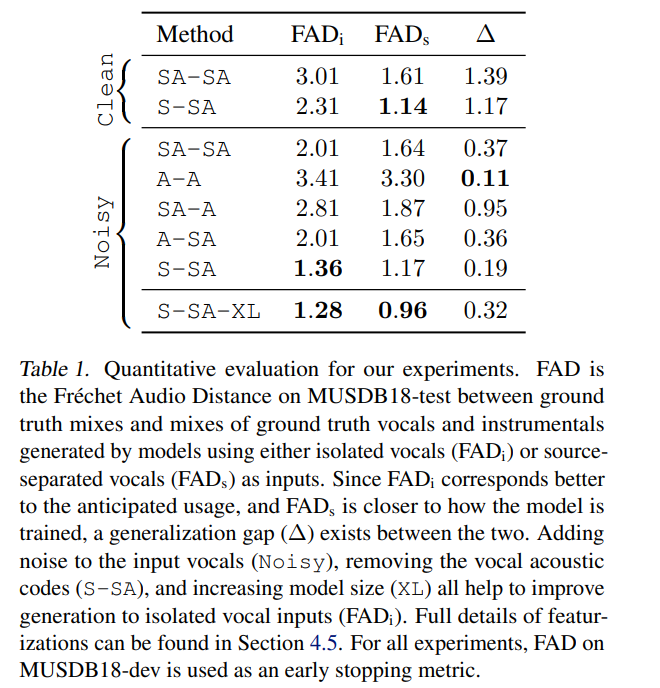
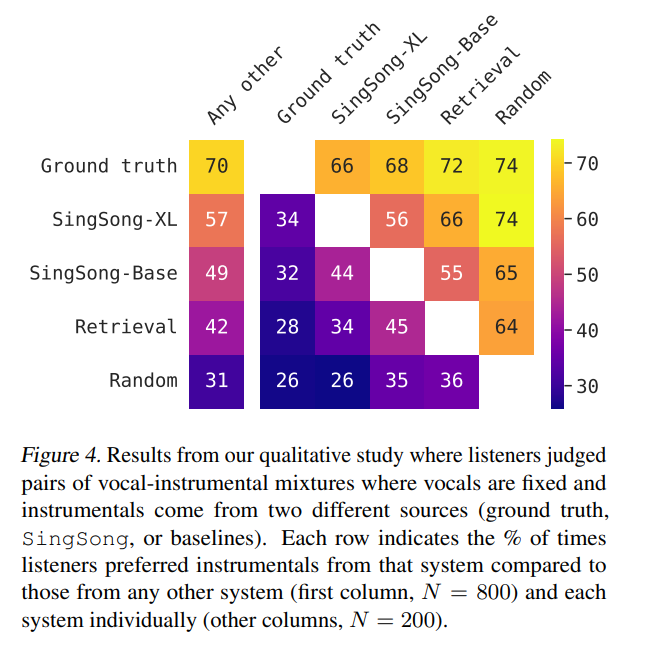
为了衡量两个最佳模型相对于基本事实和基线的定性表现,本文展开了一项听力研究。听力研究向听众展示了一对 10 秒长的声乐 - 乐器混合物,其中两种混合物中的人声是相同的,来自 MUSDB18-test,而乐器来自不同的来源(包括 ground truth,模型或基线)。研究要求听众指出这两种混合中哪一种乐器伴奏与人声在音乐上更协调,同时,为了结果的公平性,明确要求听众忽视器乐的音质保真度。
详细的系统结果见图 4。在将最好的系统(SingSong-XL)和最强的基线(Retrieval)相比较,66% 的听众可能更喜欢 SingSong-XL 中的乐器。该研究还表明,与 SingSong-Base 相比,56% 的听众更喜欢来自 SingSong-XL 的乐器(在相同的统计检验下,p = 0.01)。此外,在 57% 的情况下,听众更喜欢来自 SingSong-XL 的乐器,相比之下,最强基线中的情况只占 42%。详细比较请参见声音示例。
好了,关于配乐行业危,谷歌出手解决音乐伴奏问题,人均音乐人不远了就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “在我”忆来只把旧书读
- “科博会”芜湖科博会集中展示大国重器
- “诗人”带着大海散步的人
- “宁德”宁德时代三季报:业绩增速放缓、海外市场份额扩大
- “新材料”信金控股完成新一期人民币基金首关
- “同比增长”失守3000点后,A股市场的危与机|智氪
- “商务部”商务部:达成共识!
- “基金”又一家基金公司换董事长,年内公募高管变动人数增至321人
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “教师”北京化工大学回应学院院长被指骚扰教师:已成立工作专班,对师德失范问题零容忍
- SSP客户支付6.5亿英镑,以提前与保险软件公司退出IT平台合同
- Etsy以2.75亿美元收购乐器市场Reverb









