“模型”手机上0.2秒出图、当前速度之最,谷歌打造超快扩散模型MobileDiffusion
今天,很高兴为大家分享来自机器之心Pro的手机上0.2秒出图、当前速度之最,谷歌打造超快扩散模型MobileDiffusion,如果您对手机上0.2秒出图、当前速度之最,谷歌打造超快扩散模型MobileDiffusion感兴趣,请往下看。
在手机等移动端侧运行 Stable Diffusion 等文生图生成式 AI 大模型已经成为业界追逐的热点之一,其中生成速度是主要的制约因素。
近日,来自谷歌的一篇论文「MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices」,提出了手机端最快文生图,在 iPhone 15 Pro 上只要 0.2 秒。论文出自 UFOGen 同一团队,在打造超小扩散模型的同时, 采用当前大火的 Diffusion GAN 技术路线做采样加速。

论文地址:https://arxiv.org/abs/2311.16567
下面是 MobileDiffusion 一步生成的结果。

那么,MobileDiffusion 是如何优化得到的呢?
让我们先从问题出发,为什么优化是必须的。
当下最火的文本到图像生成都是基于扩散模型来实现的。依赖于其预训练模型强大的基本图像生成能力和在下游微调任务上的稳健性质, 我们看到了扩散模型在诸如图像编辑、可控生成、 个性化生成以及视频生成的非凡表现。
然而作为 Foundation Model, 它的不足也很明显,主要包括了两方面:一是扩散模型的大量参数导致计算速度慢,尤其是在资源有限的情况下;二是扩散模型需要多步才能采样,这进一步导致很慢的推理速度。拿最火的的 Stable Diffusion 1.5 (SD) 为例,其基础模型包含了接近 10 亿参数,我们在 iPhone 15 Pro 上将模型量化后进行推理,50 步采样需要接近 80s。如此昂贵的资源需求和迟滞的用户体验极大的限制了其在移动端的应用场景。
为了解决以上问题,MobileDiffusion 点对点地进行优化。(1) 针对模型体积庞大的问题,我们主要对其核心组件 UNet 进行了大量试验及优化,包括了将计算昂贵的卷积精简和注意力运算放在了较低的层上,以及针对 Mobile Devices 的操作优化,诸如激活函数等。(2)针对扩散模型需要多步采样的问题, MobileDiffusion 探索并实践了像 Progressive Distillation 和当前最先进的 UFOGen 的一步推理技术。
模型优化
MobileDiffusion 基于当下开源社区里最火的 SD 1.5 UNet 进行优化。在每次的优化操作后, 会同时衡量相对于原始 UNet 模型的性能的损失,测量指标包括 FID 和 CLIP 两个常用 metric。
宏观设计
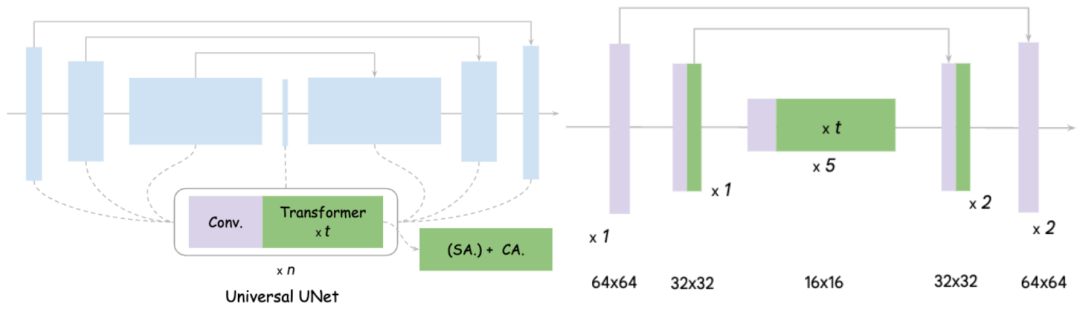
上图左边是原始 UNet 的设计示意, 可以看出基本包括了 Convolution 和 Transformer,Transformer 又包括了 Self-Attention 和 Cross-Attention。
MobileDiffusion 对 UNet 优化的核心思路分为两点:1)精简 Convolution, 众所周知,在高分辨率的特征空间上进行了 Convolution 是十分耗时的, 而且参数量很大,这里指的是 Full Convolution;2)提高 Attention 效率。和 Convolution 一样,高 Attention 需要对整个特征空间的长度进行运算,Self-Attention 复杂度和特征空间展平后长度成平方关系,Cross-Attention 也要和空间长度成正比。
实验表明将整个 UNet 的 16 个 Transformer 移到特征分辨率最低的内层,同时每一层都剪掉一个卷积,不会对性能有明显影响。达到的效果就是:MobileDiffusion 将原本 22 个 Convolution 和 16 个 Transformer,可以极致地精简到 11 个 Convolution 和 12 个左右 Transformer,并且这些注意力都是在低分辨率特征图上进行的,因为效率会极大提升,带来了 40% 效率提升和 40% 参数剪切,最终模型如上图右图所示。和更多模型的对比如下:

微观设计
这里将只介绍几种新颖的设计,有兴趣的读者可以阅读正文, 会有更详细的介绍。
Decouple Self-Attention and Cross-Attention
传统 UNet 里 Transformer 同时包含 Self-Attention 和 Cross-Attention,MobileDiffusion 将 Self-Attention 全部放在了最低分辨率特征图,但是保留一个 Cross-Attention 在中间层,发现这种设计既提高了运算效率又保证了模型出图质量
Finetune softmax into relu
softmax 众所周知在大部分未优化情况下是难以并行的,因此效率很低。MobileDiffusion 提出直接将 softmax 函数 finetune 到 relu,因为 relu 是每一个点的激活,更为高效。令人惊讶的是,只需要大概一万步的微调,模型 metric 反而提升了,出图质量也有保障。因此 relu 相比于 softmax 的优势是很明显的了。
Separable Convolution (可分离卷积)
MobileDiffuison 精简参数的关键还在采用了 Seprable Convolution。这种技术已经被 MobileNet 等工作证实是极为有效的,特别是移动端,但是一般在生成模型上很少采用。MobileDiffusion 实验发现 Separable Convolution 对减少参数是很有效的,尤其是将其放在 UNet 最内层,模型质量经分析证明是没有损失的。
采样优化
当下最常采用的采样优化方法包括了 Progressive Distillation 和 UFOGen, 分别可以做到 8 steps 和 1 step。为了证明在模型极致精简后,这些采样依然适用,MobileDiffusion 对两者同时做了实验验证。
采样优化前后和基准模型的比较如下,可以看出采样优化后的 8 steps 和 1 step 的模型,指标都是比较突出的。

实验与应用
移动端基准测试
MobileDiffusion 在 iPhone 15 Pro 上可以得到当前最快的出图速度,0.2s!

下游任务测试
MobileDiffusion 探索了包括 ControlNet/Plugin 和 LoRA Finetune 的下游任务。从下图可以看出,经过模型和采样优化后,MobileDiffusion 依然保持了优秀的模型微调能力。

总结
MobileDiffusion 探索了多种模型和采样优化方法,最终可以实现在移动端的亚秒级出图能力,下游微调应用依然有保障。我们相信这将会对今后高效的扩散模型设计产生影响,并拓展移动端应用实例。
好了,关于手机上0.2秒出图、当前速度之最,谷歌打造超快扩散模型MobileDiffusion就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “模型”手机上0.2秒出图、当前速度之最,谷歌打造超快扩散模型MobileDiffusion
- “科幻”俄科幻作家谢尔盖·卢基扬年科:中俄科幻文学有很大的共通性
- “产业”年终盘点 | 通信世界全媒体2023年度盘点系列报道即将开启!
- “北京”北京人寿14%股权遭挂牌,第一大股东北京供销社拟出清离场
- “机器人”“人体细胞机器人”问世:有自然寿命,从单个细胞中生长出,每个都独一无二
- “红包”“随礼”成当代人新型压力?爱企查盘点随份子相关专利
- “全省”四川城市居家社区“15分钟养老服务圈”基本成形,培训养老服务人才20余万人次
- “业务”国际电信联盟:进一步开展技术研究 推动国际移动通信技术应用场景扩展
- “未来”大咖云集余杭,科技照亮健康产业新航向丨未来健康论坛现场实录
- “魅族”独具光环,敢于不凡2023魅族秋季无界生态发布会顺利举行
- “模型”驶向未来,首个多视图预测+规划自动驾驶世界模型来了
- “模型”Meta教你5步学会用Llama2:我见过最简单的大模型教学
- “模型”百度刘军伟:大模型技术为医疗产业注入新引擎
- “鸿蒙”一克商评丨价格战会成为一种常态,但不代表所有的产品都需要低价
- “模型”720亿、千亿级参数大模型接连开放 国产开源大模型进入参数时代
- “模型”百度何俊杰:AI原生应用将成创新增长的“弹簧板”
- “模型”联想王传东:AI PC将成为开启大模型时代第一终端的重要角色
- “人工智能”AI一天,人间一年:如何抓住人工智能的未来趋势?
- “人工智能”大模型引爆AI算力市场 2023年中国智算规模有望同比增长近六成
- “商汤”新华社研究院:商汤“商量”获评中国大模型市场未来领袖