“代码”清华开了家员工都是GPT的公司,代码、文档一条龙服务
今天,很高兴为大家分享来自机器之心Pro的清华开了家员工都是GPT的公司,代码、文档一条龙服务,如果您对清华开了家员工都是GPT的公司,代码、文档一条龙服务感兴趣,请往下看。
我们都知道以 ChatGPT 为代表的大型语言模型(LLM)具备代码生成能力,毕竟代码本身也是一种语言。
近日,清华大学孙茂松团队不只是让 LLM 当程序员,还更进一步,基于 LLM 开发出了一家「虚拟软件开发公司」ChatDev。这家公司的各个职员都是 LLM,能端到端地完成从分析需求到写代码再到文档制作的整个软件开发流程,实现软件开发一条龙服务。理想情况下,基于该框架,用户只需提个需求,就能收获一个文档配置良好的软件!这篇论文的第一作者为清华大学软件学院毕业的钱忱博士。

论文地址 :https://arxiv.org/abs/2307.07924
软件系统的开发、运行和维护需要有条理、有原则地执行。
但是,由于开发软件需要复杂的智慧,因此很多决定往往是基于直觉和对资深开发者的有限咨询。深度学习技术的发展让研究者看到了新的可能性:能否将深度学习用于软件工程,从而提升有效性和效率并降低成本?之前已经有一些相关研究解决了一些任务,涉及软件需求、设计、实现、测试和维护。软件开发流程涉及多种工作职能,包括组织协调、任务分配、代码编写、系统测试、文档制作等。因此复杂的软件需要长时间的开发周期和对细节的高度关注。
近些年,大型语言模型(LLM)已经在自然语言处理(NLP)和计算机视觉(CV)领域取得了重大进展。简单来说,LLM 的训练范式是基于大规模语料库来「预测下一个词」;而训练得到的模型能出色应对许多不同的下游任务,如上下文感知型问答、机器翻译和代码生成。事实上,软件开发的核心元素(即代码和文档)其实都可以被视为「语言」,即字符序列。
基于这一思考,清华大学、北京邮电大学和布朗大学的一个研究团队设计了一种框架,可用 LLM 来实现端到端的软件开发。据介绍,该框架涵盖了整个开发流程,包括分析需求、代码开发、系统测试和文档生成,目标是为软件开发提供一个统一、高效、低成本的范式。
研究者的做法并非用 LLM 直接生成整个软件系统,因为这会出现一些代码幻觉(code hallucinations)问题,类似于自然语言知识查询中的幻觉现象。这些幻觉包括功能实现不完整、缺少依赖以及尚未发现的可能错误。出现代码幻觉的原因主要有两个。
第一,当一步式地生成软件系统时,由于难以指定具体任务,LLM 会感到困惑。LLM 在处理高层级任务时缺乏细粒度思考,比如分析用户 / 客户需求和选择编程语言,而这些细粒度任务能为软件开发提供引导。
第二,决策过程缺乏交叉检查具有重大风险。不同的模型示例给出的答案也不尽相同,这就需要辩论和检验各个模型的响应,进而收敛到单个或多个更准确的共同答案。这类措施包括代码同行评审和建议反馈。
为了解决前述难题,这些研究者的做法是创立一家虚拟公司。当然,这并不是一家真正的公司,而是以公司模式运行的一个模型框架。他们为其起名为 ChatDev。
该框架遵循经典的瀑布模型(Waterfall Model),将开发过程分成了四个阶段:设计、写代码、测试和做文档。
ChatDev 在每个阶段都会使用多个不同的智能体,它们充当着公司的不同角色,比如程序员、评审员和测试员。
为了促进有效的沟通和协作,研究者为 ChatDev 提出了一种名为聊天链(chat chain)的设计,即将每个阶段都切分为易于执行的原子级子任务。在聊天链中,每个节点代表一个特定的子任务,两个角色参与可感知上下文的多轮讨论,进而提出并验证解决方案。这种方法能确保客户需求得到分析、产生出创意思路、设计并实现原型系统、识别和解决潜在问题、解释调试信息、创建吸引人的图形界面并生成用户手册。通过沿聊天链引导软件开发过程,ChatDev 能将最终的软件交付给用户,包括源代码、依赖环境规范和用户手册。
研究者通过实验检验了这一框架的可行性:他们设计了 70 个用户需求,然后分析了 ChatDev 产出的软件。平均而言,ChatDev 生成的每个软件有 17.04 个文件、缓解由代码幻觉引起的潜在代码漏洞 13.23 次、软件生成时间为 409.84 秒、制造成本为 0.2967 美元。
实验中,讨论发挥了巨大作用:评审员和程序员之间的讨论成功识别出并修改了近 20 种代码漏洞类型,而测试员和程序员之间的讨论则成功找到了 10 多种可能漏洞并进行了修改。
本文的主要贡献包括:
提出了 ChatDev,这是一个基于聊天的软件开发框架。用户只需简单指定一项任务,ChatDev 就会按顺序进行设计、写代码、测试和做文档。这种新范式通过语言交流统一了主要开发流程,从而无需在每个阶段都使用专门的模型,这能极大简化软件的开发过程。
研究者提出了聊天链,可将开发流程分解成按顺序执行的原子级子任务。每个子任务都需要两个角色之间的协作交互和交叉检查。该框架支持多智能体协作、用户对中间输出进行检查、错误诊断和推理得出干预措施。这能确保对每次聊天中的特定子任务进行细粒度的关注,促进有效的协作,帮助得到所需的输出。
为了进一步缓解与代码幻觉相关的潜在难题,研究者引入了思维指示(thought instruction)机制,可用于写代码、审查和测试阶段的每个独立聊天过程。通过执行「角色翻转」,指示员可将修改代码的具体思路明确地注入到指令中,从而更精准地引导辅助程序员。
研究者进行了实验验证,结果表明 ChatDev 能有效且高效地自动完成软件开发过程。通过每次聊天中角色之间的有效沟通、建议和相互审查,该框架可以实现有效的决策。
ChatDev
ChatDev 的大致架构如图 1 所示,这是一家聊天驱动的软件技术「虚拟公司」,其中包含不同的职能角色,它们对应于真实公司的不同职业岗位,比如各种首席官、专业程序员、测试工程师和艺术设计师。当接到任务时,ChatDev 的不同智能体将协作开发所需的软件,包括可执行系统、环境指南和用户手册。这种范式的核心思路是利用大型语言模型作为核心思考组件,使智能体模拟整个软件开发过程,避免额外的模型训练需求,并在一定程度上减轻代码幻觉问题。
 图 1:ChatDev 的大致架构
图 1:ChatDev 的大致架构聊天链
ChatDev 采用被广泛应用的瀑布模型,将软件开发过程分成了四个不同阶段:设计、写代码、测试和做文档。每个阶段都需要多个角色之间有效沟通,而其中的难点就在于确定互动顺序和参与角色。
这里,研究者提出的解决方案是将每个阶段分解为多个原子级聊天,每个聊天都特定关注面向任务的两个不同角色的角色扮演。通过参与智能体之间的指令交换和协作,可以让每个聊天都输出所需结果,而这些结果是构成目标软件的重要组成部分。
图 2 描述了这个过程,其中展示了一个解决中间任务的聊天序列。在每次聊天中,指示员都会发出指令,引导对话完成任务,而助手则遵循指令,提供合适的解决方案,并参与可行性讨论。指示员和助手通过多轮对话互相协作,直至达成共识,确定任务成功完成。
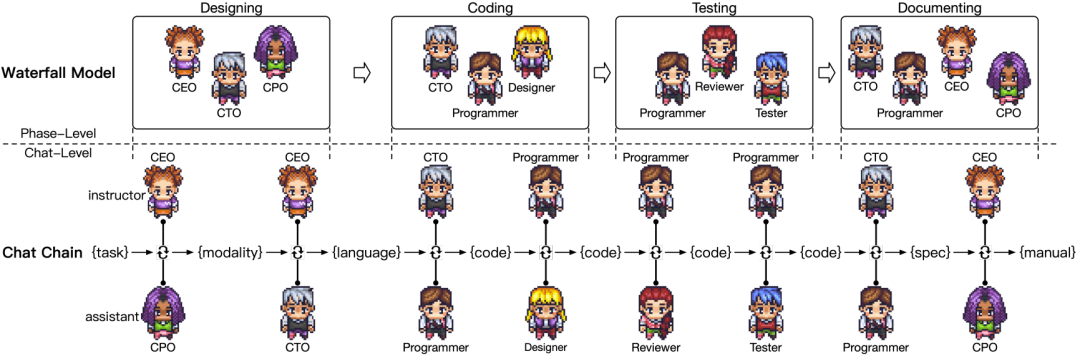 图 2:新提出的 ChatDev 架构,其中包含阶段级组件和聊天级组件
图 2:新提出的 ChatDev 架构,其中包含阶段级组件和聊天级组件设计
在设计阶段,ChatDev 从人类客户处获得一个想法。该阶段涉及三个预定义角色:CEO(首席执行官)、CPO(首席产品官)和 CTO(首席技术官)。然后,聊天链将设计阶段分解为按顺序执行的原子级聊天任务,包括决定目标软件模式的聊天(CEO 和 CPO)和决定编程语言的聊天(CEO 和 CTO)。
1.角色分配
在角色扮演过程中,使用系统提示 / 消息为每个智能体分配角色。与其它典型的对话语言模型相比,新框架的提示工程仅限于角色扮演场景的初始阶段。在这个框架中,指示员最初是作为 CEO,参与互动规划,而助手则承担 CPO 的角色,执行任务和提供响应。
为了实现角色专业化(role specialization),研究者采用了初始提示(inception prompting),事实证明这可以有效地使智能体履行其角色职能。指示员和助手 prompt 包含很多重要细节,比如指定的任务和角色、交流协议、终止标准和旨在防止不良行为(如指令冗余、无信息响应、无限循环等)的约束。
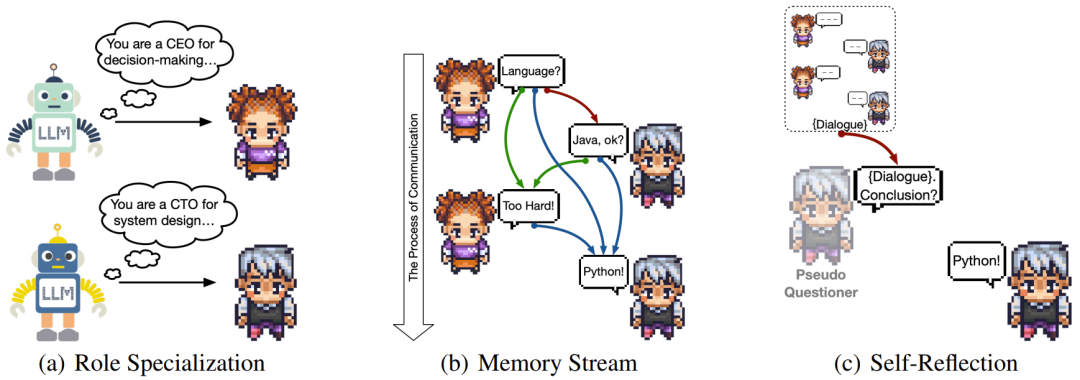 图 3:每次聊天中使用的三个关键机制:角色专业化、记忆流、自我反思
图 3:每次聊天中使用的三个关键机制:角色专业化、记忆流、自我反思2.记忆流(Memory Stream)
记忆流机制的作用是维持智能体之前对话的全面记录,以一种可感知话语的方式辅助后续决策。有关记忆流的形式化描述,请参看原论文。
3.自我反思
研究者观察到,有时候对话双方已达成共识,但没有触发作为终止条件的预定义的交流协议。为此,他们引入了自我反思机制,其中涉及到对记忆的提取和检索。为了实现这一机制,研究者引入一个「伪自我」,将其作为质疑者来发起新聊天。这个伪质疑者会将所有之前对话的历史记录告知当前助手并要求对对话中的结论性信息进行摘要,如图 3 (c) 所示。
这一机制能有效地鼓励助手反思对话期间提出和讨论的决定。
写代码
该阶段涉及三个预定义角色:CTO、程序员和艺术设计师。聊天链会将写代码阶段分解为按顺序执行的原子级聊天任务,例如生成完整的代码(CTO 和程序员)和设计图形用户界面(设计师和程序员)。
基于上一阶段讨论的主要设计,CTO 会指示程序员使用 Markdown 格式实现软件系统。程序员的响应是生成代码,并根据 Markdown 格式提取出对应的代码。设计师的任务是提出一种对用户友好的图形用户界面(GUI),它可使用图形图标进行用户交互,而非文本命令。然后,设计师使用外部的文本转图像工具创建吸人眼球的图形,程序员再使用标准的工具包将其整合到 GUI 设计中。
1.代码管理
为了应对复杂的软件系统,ChatDev 使用了 Python 等面向对象的编程语言。面向对象的编程是模块化的,这能实现自包含的(self-contained)对象,有助于故障排除和协作开发。可复用性支持通过继承实现代码复用,减少冗余。
研究者引入了「版本演进」机制来限制角色之间最新代码版本的可见性,从记忆流中丢弃早期的代码版本。程序员使用 Git 相关命令来管理项目。提议的代码修改和更改会将软件版本号增加 1.0。版本演进可逐渐消除代码幻觉。面向对象编程与版本演进相结合,适合涉及长段代码的对话。
2.思维指示
传统的问答可能会导致出现不准确或不相关的信息,特别是在代码生成中,简单直接的指令可能会导致意想不到的幻觉。在生成代码时,这个问题变得尤其突出。
为了解决这个问题,研究者在「思维链提示」的启发下提出了「思维指示(thought instruction)」机制。这涉及到在指令中明确解决特定的问题求解思路,类似于按顺序解决子任务。如图 4 (a) 和 4 (b) 所示,思维指示包括交换角色以询问哪些方法尚未实现过,然后切换回来,从而为程序员提供更精确的指示。
通过整合思维指示,写代码过程会变得更关注重点和有针对性。指令中特定思维的明确表达有助于减少歧义并确保生成的代码与预期目标保持一致。这种机制可让写代码过程更准确且实现上下文感知,从而最大限度地减少幻觉,输出更可靠更全面的代码。
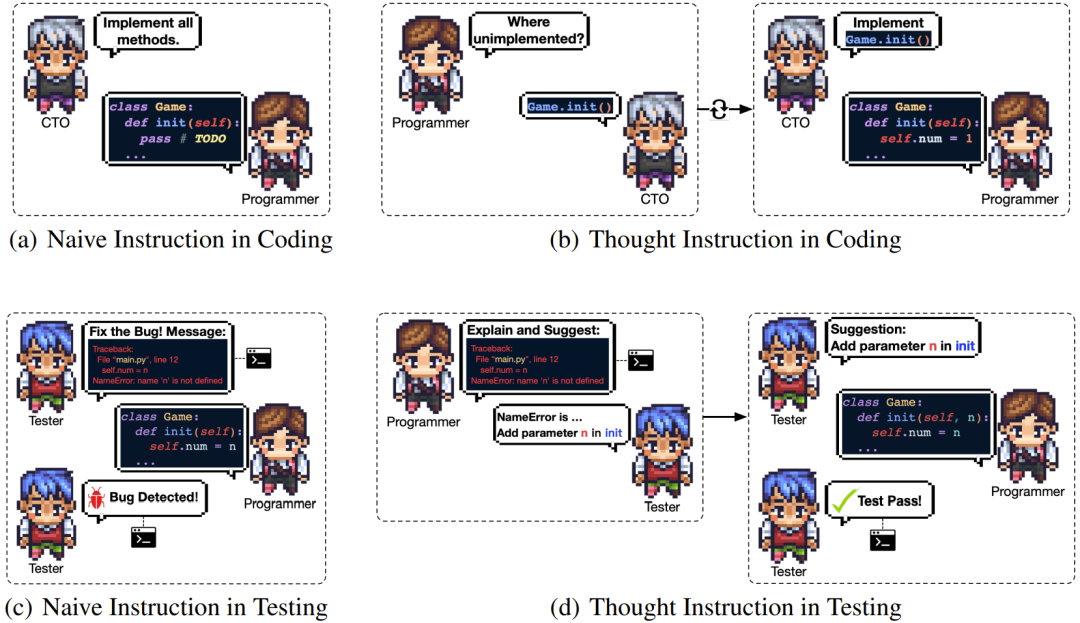 图 4:思维指示可缓解编码和测试阶段的代码幻觉
图 4:思维指示可缓解编码和测试阶段的代码幻觉测试
即使人类程序员也不能保证自己第一次尝试编写的代码始终没有错误。人类通常不会直接丢弃不正确的代码,而会分析和调查代码执行结果以识别和纠正实现中的错误。ChatDev 的测试阶段涉及三个角色:程序员、审查者和测试者。
这个过程包含的原子级任务有同行评审(程序员和审查员)和系统测试(程序员和测试员)。同行评审是静态调试,目的是通过检查源代码来识别潜在问题。系统测试是一种动态调试,目的是通过程序员使用解释器执行测试,从而验证软件的执行情况。该测试的重点是通过黑盒测试评估应用程序的性能表现。
如果解释器难以找到细粒度的逻辑问题,则可以让人类客户参与到软件测试中。
写文档
经过设计、写代码和测试阶段之后,ChatDev 使用四个智能体(CEO、CPO、CTO 和程序员)来生成软件的项目文档。研究者的做法是使用大型语言模型,通过基于上下文样本的少样本 prompt 设计来生成文档。CTO 指示程序员提供环境依赖项的配置指令,从而生成像 requirements.txt 这样的文档。该文档可让用户独立地配置环境。与此同时,CEO 可向 CPO 传达需求和系统设计,让 CPO 生成用户手册。
 图 5:文档生成过程
图 5:文档生成过程实验
实验使用了 gpt3.5-turbo-16k 版本的 ChatGPT 来模拟多智能体软件开发,具体的参数设置请参看原论文,下面我们看看实验结果。
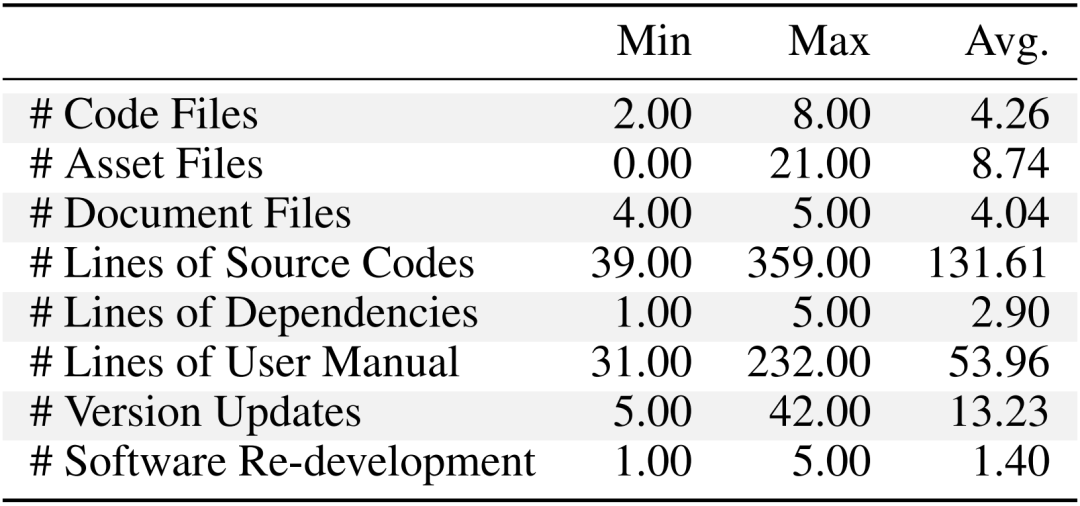 表 1:ChatDev 的软件开发的统计数据分析,包括各方面数值的最小值(Min)、最大值(Max)和平均值(Avg.)
表 1:ChatDev 的软件开发的统计数据分析,包括各方面数值的最小值(Min)、最大值(Max)和平均值(Avg.)ChatDev 开发的软件通常会生成 39-359 行代码,平均 131.61 行。数据表明 ChatDev 倾向于产出代码规模相对较小的软件。部分原因是面向对象编程的设计,其可复用性可以通过继承实现代码重用,减少冗余。
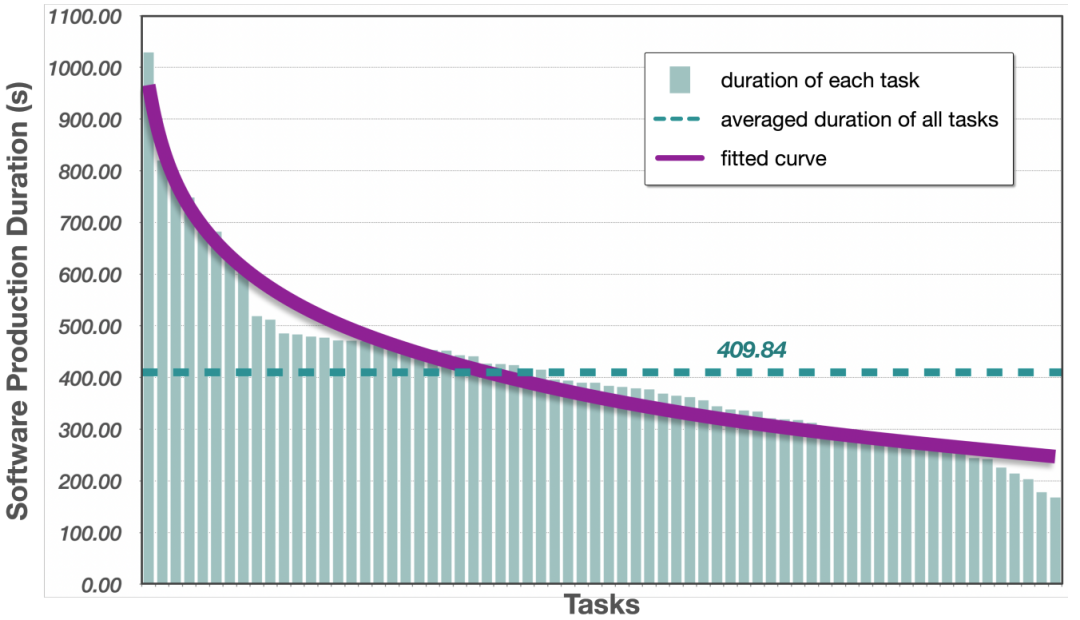 图 6:持续时间分布。图中的条形按降序排列,展示了不同任务的软件开发运行时间的分布情况。
图 6:持续时间分布。图中的条形按降序排列,展示了不同任务的软件开发运行时间的分布情况。平均而言,使用 ChatDev 开发小型软件和界面需要 409.84 秒,不到 7 分钟。相比之下,传统的定制软件开发周期,即使是使用敏捷软件开发方法,每个周期通常也需要 2-4 周甚至几个月时间。
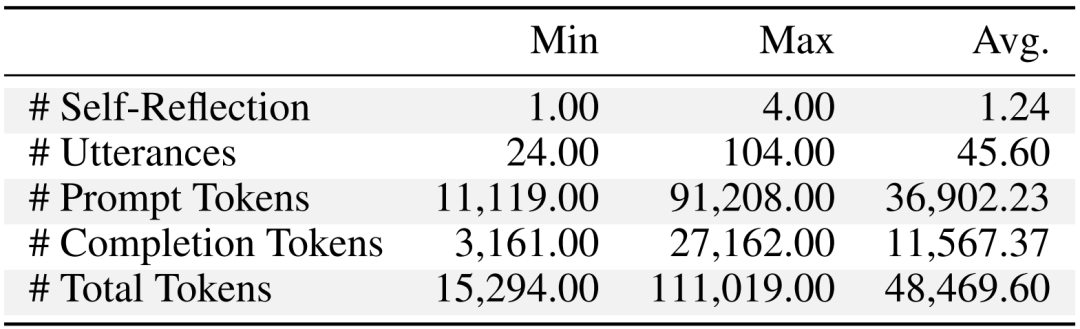 表 2:聊天链中所有对话的统计分析
表 2:聊天链中所有对话的统计分析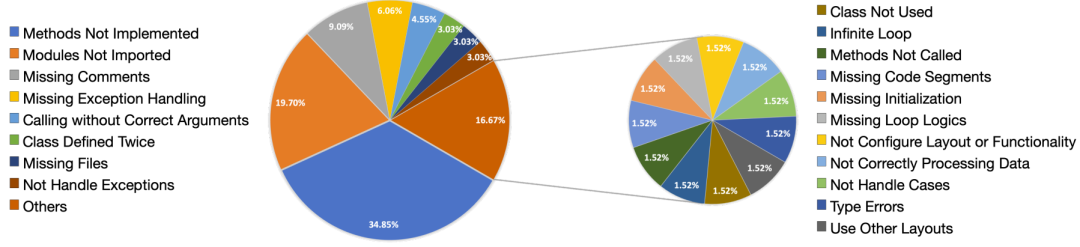 图 7:审查者建议的分布情况。饼图中的每种颜色代表审查者提供的特定建议的类别。
图 7:审查者建议的分布情况。饼图中的每种颜色代表审查者提供的特定建议的类别。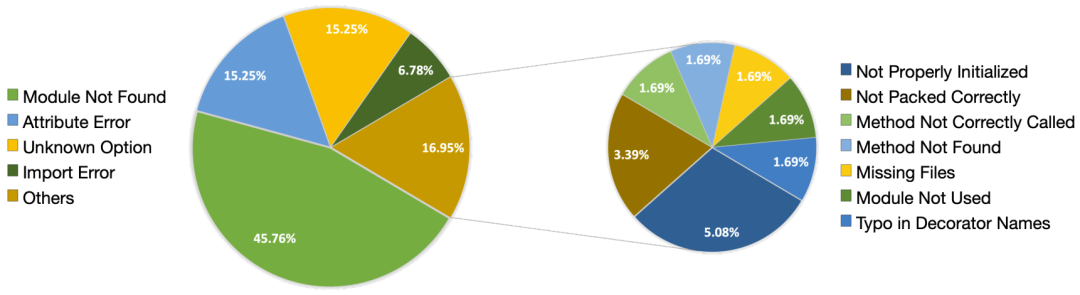 图 8:测试者建议的分布情况。饼图中的每种颜色代表测试者提供的漏洞的类别。
图 8:测试者建议的分布情况。饼图中的每种颜色代表测试者提供的漏洞的类别。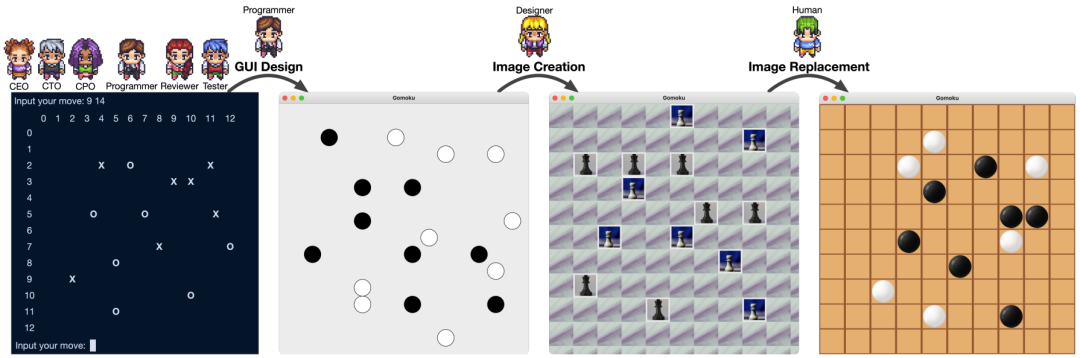 图 9:任务「design a basic Gomoku game」(设计一个基础五子棋游戏)所得到的软件
图 9:任务「design a basic Gomoku game」(设计一个基础五子棋游戏)所得到的软件左边是一个没有 GUI 的简单软件。该版本的游戏只能通过命令终端来玩,其交互性和整体趣味性有限。相比之下,通过结合 GUI 设计,ChatDev 可以创造出视觉上好看的小游戏。此外,ChatDev 的设计师还可以协助程序员创建额外的图形,以增强 GUI 的美观性和可用性。
最后我们看看 ChatDev 公司开发五子棋游戏时,职员讨论如何选择编程语言的聊天概况:

好了,关于清华开了家员工都是GPT的公司,代码、文档一条龙服务就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “铜陵”化工厂爆炸?两名造谣者被查处
- “爷爷”爷爷的石榴树
- “陈老”高山仰止,景行行止 ——读春桃老师所著《国医》
- “知网”中国知网用户委员会两名成员公开亮相
- “宜宾”近2万人参加!2023宜宾长江马拉松开跑:埃塞俄比亚选手包揽全马组男女前三名
- “鲁南”鲁南制药集团建厂55周年:“向新向未来”
- “民谣”玉林民谣,从成都走向深圳
- “亿元”爱仕达董事长陈合林做铁锅起家 公司已连续亏损两年多他有啥招术?
- “营收”“酱油一哥”黯然失色!市值蒸发超5000亿,海天味业遭转型阵痛
- “可持续”“京澳25”公益计划启航
- “问答”ChatGPT重压下,Stack Overflow裁员28%,为自家生成式AI工具开源节流
- “之家”(更新)苹果 App Store 下架伪装成学习软件的黄色软件,免费榜第一再现黄色软件
- “软件”AutoCore完成B2轮融资
- “法国”苹果向法国提交iPhone 12软件更新:解决辐射超标问题
- “思科”新思科技付红勋:AIGC时代带来更大应用安全机会
- “代码”程序员如何用ChatGPT编程?
- “代码”大模型写代码能力突飞猛进,北大团队提出结构化思维链SCoT
- “项目”狂揽13k star,开源版代码解释器登顶GitHub热榜,可本地运行、可访问互联网
- “智能”IDC:2022 年中国 PLM 软件市场总规模达到24.9 亿元人民币 年增长率为 17.1%
- “之家”恶意软件 AMOS 威胁升级:在谷歌搜索投放广告、钓鱼诱骗 Mac 用户安装









