“算法”能胜任统计学家?Transformers超强学习机制「自动算法选择」
今天,很高兴为大家分享来自机器之心Pro的能胜任统计学家?Transformers超强学习机制「自动算法选择」,如果您对能胜任统计学家?Transformers超强学习机制「自动算法选择」感兴趣,请往下看。
Salesforce AI Research、北京大学和 UC 伯克利合作的最新论文,发现 Transformer 模型在上下文中学习(in-context learning)的新机制:「自动算法选择」,类似统计与机器学习专家能够现实完成的工作。
ChatGPT 等基于 Transformer 的大语言模型具备极强的在上下文中学习(In-Context Learning,ICL)的能力:输入少量示例样本,即能够正确回答同类问题。如何理解这种 ICL 能力?
本文作者实验发现并证明一种 ICL 的新机制:自动算法选择,可以允许单一 Transformer 模型在不同输入数据上选择执行完全不同的,适合该数据的学习算法,类似统计与机器学习专家能够现实完成的工作。基于量化的 Transformer 构造,文章一并给出 Transformer 实现 ICL 的一套全面的统计理论,包含近似精度,预测表现,以及预训练的样本复杂度。

论文地址:https://arxiv.org/abs/2306.04637
Transformer 能在 ICL 中完成机器学习任务
ChatGPT 等基于 Transformer 的大模型可以根据输入的文本,自上下文中学习。如何系统地理解这种能力?NeurIPS 2022 的一篇论文(Garg et al. 2022)考察了 Transformer 从上下文中进行机器学习任务的能力。
将 N 个训练样本与 1 个测试样本 (x_1, y_1, …, x_N, y_N, x_{N+1}) 作为一个序列输入 Transformer,要求 Transformer 输出 y_{N+1}。这些样本来自简单的统计模型,例如线性模型,但每个序列由不同的模型参数(w_\star)生成。Transformer 如果想总是正确地预测 y_{N+1},那么就需要从训练样本中学习真正的参数 w_\star,并利用其进行预测。
Garg et al. 发现,训练好的 Transformer 总是能够精准地预测 y_{N+1},并且预测表现能够媲美该数据上的最优算法。例如线性模型上,Transformer 的预测效果可以媲美最小二乘法(Least Squares),稀疏线性模型上媲美 Lasso,决策树上能超过 Gradient Boosting。
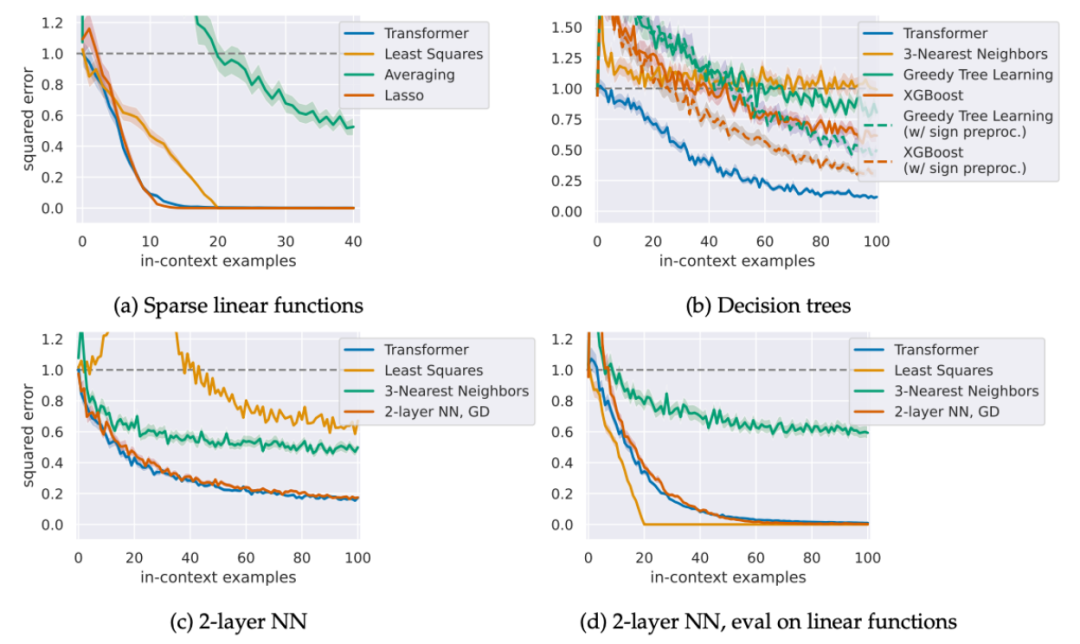
Transformer 虽然在各个任务中实现最优算法,然而这些算法都只是标准的机器学习算法,远不能完全解释 ChatGPT 等大模型强大的 ICL 能力。还存在更强的机制吗?
自动算法选择
现实生活中,统计学家与机器学习专家会如何分析数据?给定一个数据集,统计学家会先确定数据的结构,规模等,然后根据数据的特点选择最适合的算法。如果不确定哪个算法合适,则会同时尝试多个算法,然后利用验证集(validation split)或交叉验证(cross-validation)等选择表现最好的算法。
本文作者发现,Transformer 也能够进行类似的自动算法选择。自动算法选择允许一个单独的 Transformer 模型,在不同的 ICL 问题上选择不同的算法,类似统计学家可以现实完成的工作。
作者给出两种一般的算法选择机制,从理论上证明 Transformer 模型可以实现这两个机制,并且实验上验证了 Transformer 能够近似实现这两种机制,达到了比单一机器学习算法更强的效果。
机制 1:用验证集做算法选择
在这一机制中,Transformer 先将输入数据分为训练集和验证集。接下来在训练集上同时执行 K 个算法,然后在验证集上测试 K 个算法的表现,最终用表现最好的算法 k_star 给出预测。
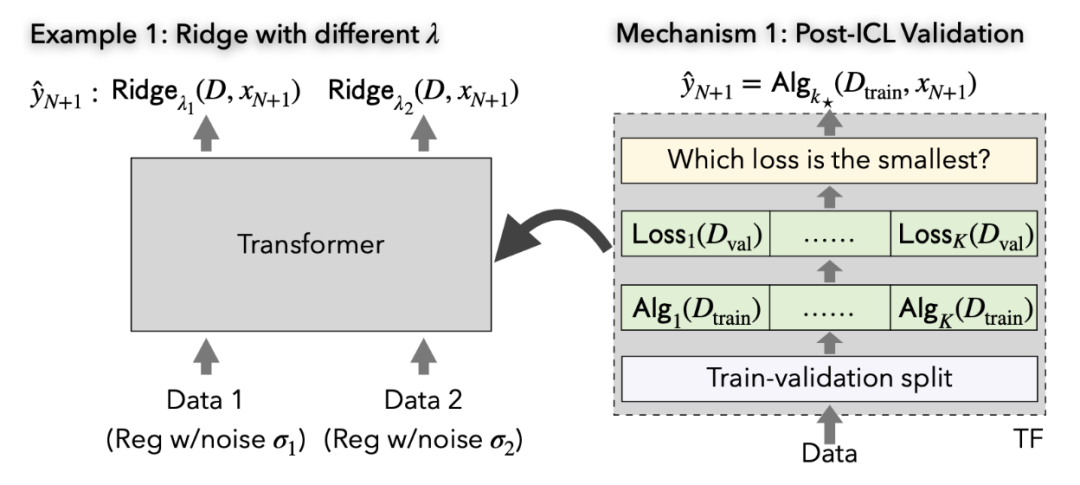
应用这一机制,Transformer 可以完成一大类算法选择。如下图当中,通过恰当的预训练,Transformer 可同时实现在两个带不同正则化的 ridge regression 算法,并对具体数据分布实现较优的那个算法。进一步,对这一任务,我们在理论上也能够证明 Transformer 能够近似整个任务的 Bayes 最优表现。

Figure 3: 单一 Transformer 可以在两个带不同噪音的线性模型中同时接近最优。在每个模型中,Transformer 的预测都接近该模型上 Bayes 最优算法(带不同正则化的 ridge regression)。
机制 2:提前对数据分布进行检验
在这一机制中,Transformer 通过提前检验数据分布(如计算一些统计量),来决定恰当的算法。例如在下图当中,单一的 Transformer 可以在回归问题上实现回归算法(如线性回归),在分类问题上实现分类算法(如 Logistic Regression)。
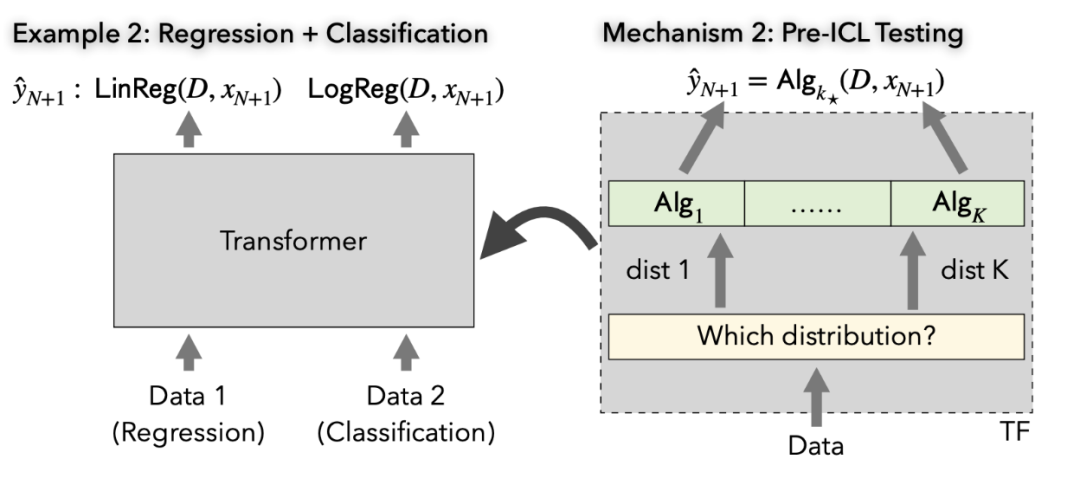

Figure 5: 单一 Transformer 可以同时在回归问题和分类问题上接近最优表现:在回归问题上表现接近最小二乘法,在分类问题上接近 Logistic Regression。
理论框架
除了自动算法选择,本文的另一大贡献是给出了 Transformer 进行 ICL 的一套完整的统计学习理论,涵盖
Transformer 如何实现各种机器学习算法的具体构造,如最小二乘法,Lasso,ridge regression,解广义线性模型的凸优化算法,神经网络上的梯度下降法等;
对上述 Transformer 大小(层数、attention head 个数、权重矩阵的范数)的精确界;
上述 Transformer 在标准统计假设下,在 ICL 中的预测表现;
Transformer 实现自动算法选择时类似的保证;
通过预训练 Transformer 达到上述效果的样本复杂度。
这套理论给出了 Transformer 进行 ICL 的一整套分析框架。作者相信这一框架可以推广到一大类相关问题当中,给出类似的理论保证。
结语
本文从理论和实验上发现 Transformer 模型在 ICL 中能够进行自动算法选择,并给出了一整套进行 ICL 的理论框架。
基于本文的结论还有很大的探索空间,例如其它进行 ICL 或自动算法选择的机制;在 ICL 中逼近 Bayes 最优表现的其它机制;预训练的 Transformer 如何实现算法选择的内部机理;对其它 ICL 任务的分析。作者相信,对这些问题的进一步探索,能对大模型有更多有趣的发现。
作者简介
本文作者 Yu Bai 现任 Salesforce Research 资深研究科学家。Fan Chen 本科毕业于北京大学,即将博士入学麻省理工大学。Huan Wang、Caiming Xiong 分别现任 Salesforce Research 研究主管及副总裁。Song Mei 现任 加州大学伯克利统计系助理教授。
好了,关于能胜任统计学家?Transformers超强学习机制「自动算法选择」就讲到这。
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“科技金融网”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场,如有侵权,请联系我们删除。
相关文章
- “铜陵”化工厂爆炸?两名造谣者被查处
- “爷爷”爷爷的石榴树
- “陈老”高山仰止,景行行止 ——读春桃老师所著《国医》
- “知网”中国知网用户委员会两名成员公开亮相
- “宜宾”近2万人参加!2023宜宾长江马拉松开跑:埃塞俄比亚选手包揽全马组男女前三名
- “鲁南”鲁南制药集团建厂55周年:“向新向未来”
- “民谣”玉林民谣,从成都走向深圳
- “亿元”爱仕达董事长陈合林做铁锅起家 公司已连续亏损两年多他有啥招术?
- “营收”“酱油一哥”黯然失色!市值蒸发超5000亿,海天味业遭转型阵痛
- “可持续”“京澳25”公益计划启航
- “结构”结核杆菌致病机制获揭示
- “模型”解决大模型复现难、协作难, 这支95后学生团队打造了一个国产AI开源社区
- “模型”人工智能公司OpenCSG发布大模型开源生态社区“传神”
- “模型”北理工团队在人工智能图像识别领域取得新进展
- “模型”参数少近一半,性能逼近谷歌Minerva,又一个数学大模型开源了
- “模型”评论能力强于GPT-4,上交开源13B评估大模型Auto-J
- “模型”端侧首次实现70亿AI语言大模型 联发科vivo强强联手
- “模型”中国信通院承接工信部大模型公共服务平台建设工作,联合 360、京东、商汤等
- “融资”国内AI大模型赛道火热,大厂积极跟投布局
- “模型”在RTX 4090被限制的时代下,让大模型使用RLHF更高效的方法来了









